Dear digitalists,
In my last post, I shared a rather lengthy write-up of a geospatial data project I’ve been working on–I hope that some of it is helpful!
Aiming for brevity in this post (and apologies for hogging the blog), I’d like to see if anyone has feedback for part two of the mapping project I’m working on currently. To summarize the project in brief, borrowing directly from my last post: “Driven by my research interests in the spatiality of imaginative reading environments and their potential lived analogues, I set out to create a map of the Icelandic outlaw sagas that could account for their geospatial and narrative dimensions.”
While you can check out those aforementioned geospatial dimensions here, the current visualization I’ve created for those narrative dimensions seems to be lacking. Here it is, and let me describe what I have so far:
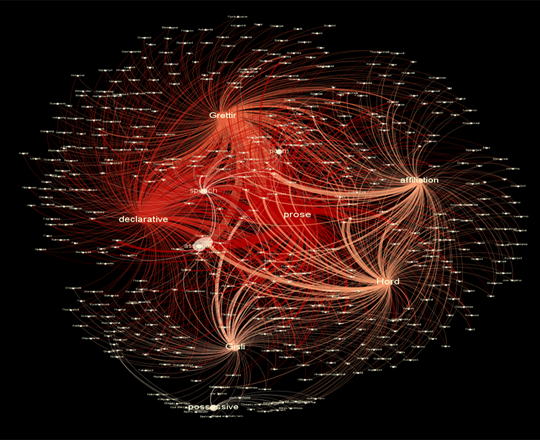
Click through for interactive Sigma map
I used metadata from my original XML document, focusing on categories for types of literary or semantic usage of place name in the sagas. I broadly coded each mention of place name in the three outlaw sagas for what “work” it seemed to be doing in the text, featuring the following categories: declarative (Grettir went to Bjarg), possessive (which included geographic features that were not necessarily a place name, but acting as one through the possessive mode, such as Grettir’s farm), affiliation (Grettir from Bjarg) and whether the place name appeared in prose, poetry, or an embedded speech. Using open-source software Gephi, this metadata was transformed into nodes and edges, then arranged in a force algorithm according to a place name weight that accounted for frequency of mentions across the sagas. I used the JavaScript library Sigma to embed the Gephi map into the browser.
While I feel that this network offers a greater degree of granularity on uses of place name, right now I feel also that it has two major weaknesses: 1) it does not interact with the geographic map, and 2) I am not sure how well it captures place name’s use within the narrative itself.
My question to you, fellow digitalists: what are ways that I could really demonstrate how place names function within a narrative? Should I account for narrative’s temporal aspect–the fact that time passes as the narrative unfolds, giving a particular shape to the experience of reading that place names might inform geographically? How could I get an overlay, of sorts, on the geospatial map itself? Should I consider topic modelling, text mining? Are there potential positive aspects of this Gephi work that might be worth exploring further?
Submitting to you, dear readers, with enormous debts of gratitude in advance for your help! And even if you don’t consider yourself a literary expert–please chime in. We all read, and that experience of how potentially geographic elements affect us as readers and create meaning through storytelling is my most essential question.