PROJECT:
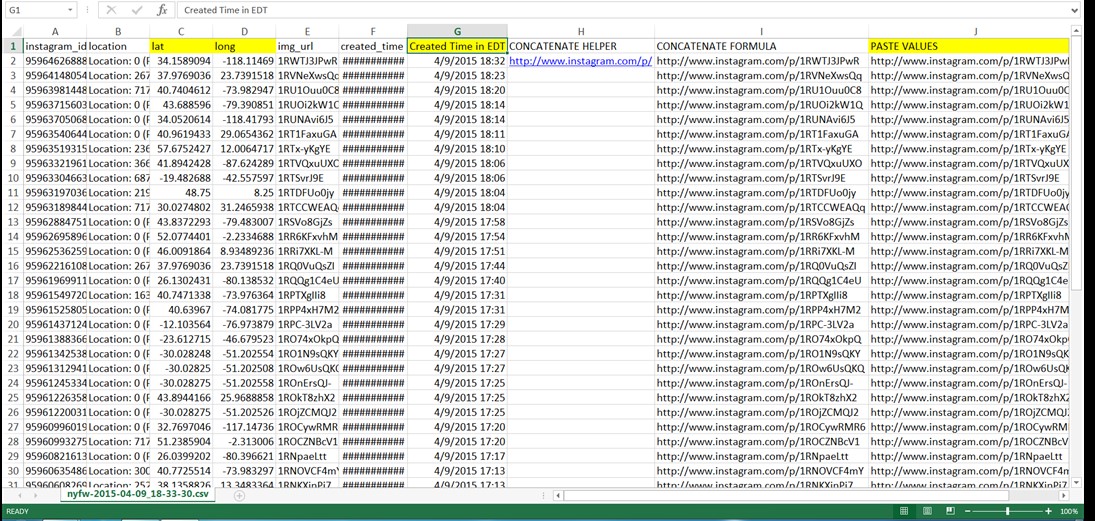
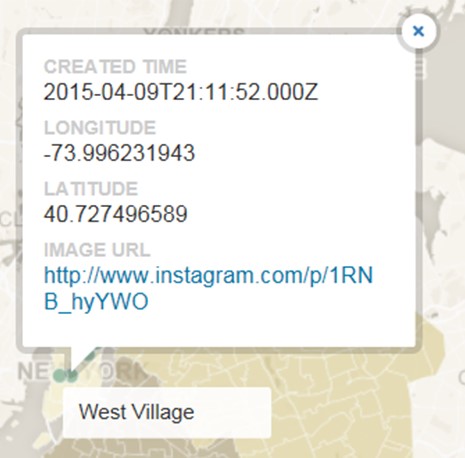
TANDEM 0.5 will be moving from it’s heavy development phase into a testing and forward-facing design phase this week. At the time of this posting, Steve and Chris are still working out the specifics of functioning unified code, but testing of the independent scripts has begun to a certain degree of success. Text and image values are easily generated via independent processes.
This week we also discussed the idea of data persistence with some depth. Simply put, would someone be able to access the data they generated at a later date via the TANDEM ui. At this iteration of the software, we agree that this is a valuable component, but not an essential feature for an MVP. That said, we are thinking about both the code needed to run it and the user-specific UI that would accompany such an application.
DEVELOPMENT:
We are working away at unifying TANDEM’s independently functioning image and text codebases. We are aligning the code in a single python script file. We vetted an idea to have two scripts, one for image and one for text, run simultaneously. The decision was made that for this first iteration of TANDEM, a single .py will suffice, and in fact may be more maintainable and more efficient.
The code merge has been slow due to python versioning issues which lead to the code producing different results on different machines.
A call is scheduled for Tuesday with Tim at Reclaimhosting to work on configuring the server to run Django. Meanwhile the developer is working through the very thorough Django tutorial and also trying to begin the defined appropriate class objects for a potential future version.
DESIGN:
Immediately following the code merge, we plan to begin implementing our user interface. A full size mockup of this is still under version control as we explore new grounds with user-specific views and the possibility of in-browser table views of the .csv data that is generated.
OUTREACH:
TANDEM continues to reach new communities. We have a lead, thanks to Sarah Cohn. The Biodiversity Library is currently crowdsourcing their seed catalog archive project, and in advanced versions, TANDEM might improve their information collection. http://blog.biodiversitylibrary.org/2015/03/help-us-improve-access-to-seed-and.html Jojo will contact them once our prototype is more stable.
Additionally, Jojo spoke with Grant Wythoff, who reasserted TANDEM’s relevance to Bill Gleason’s project at the Cotsen Library. Jojo will reach out to Professor Gleason again this week. Grant also recommended we contact Natalie Houston at University of Houston regarding her Digital Victorian project on the visuality of poetry.
Jojo also attended the DjangoGirlsNYC event at the Stack Exchange. In addition to familiarizing herself with the framework in which TANDEM will eventually operate, she made useful contact with other django developers working in NYC.