Statistics and R
I am pursuing two unrelated paths. The first of which is a collaborative path with Joy. She has identified some interesting birth statistics. The file we started with was a PDF downloaded from the CDC (I believe). I used a website called zamzar.com to convert the PDF to a text file. The text file was a pretty big mess, because it included a lot of text in addition to the tabular data that we are interested in.
Following techniques that Micki demonstrated in her Data Visualization Workshop, I used Text Wrangler to cut out a single table and gradually clean it up. I eliminated commas in numeric fields, and extra spaces. I inserted line feeds etc. until I had a pretty good tab-delimited text file, which imported very cleanly into Excel, where I did some additional cleaning and saved the table as a CSV file that would work well in R. The table reads into R very cleanly so that we can perform simple statistics on it such median, min and max.
Text Analysis
My other data path is working with text, specifically, Dickens’ “Great Expectations”. I have used no fewer than three different tools to open some windows onto the book First a loaded a text file version of the book into Antconc, “…a freeware tool for carrying out corpus linguistics research and data-driven learning.” I was able to generate word counts and examine word clusters by frequency. The tool is very basic so until I had a more specific target to search, I set Antconc aside.
At Chris’s suggestion I turned to a website called Voyant-tools.org, which quickly creates a word cloud of your text/corpus. What it does nicely is provide the ability to apply a list of stop words, which eliminates many common frequently used words, such as ‘the’ and ‘to’. Using Voyant, I was able to very quickly create a word cloud and zero in on some interesting items.
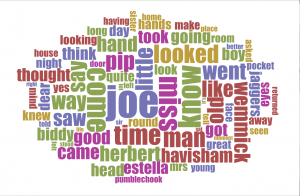
The most frequently mentioned character is Joe (in fact, Joe is the most frequent word) and not Pip or Miss Havisham. That discovery sent me back to Antconc to understand the contexts in which Joe appears . Other words that loom large in the word cloud and will require further investigation are ‘come’ & ‘went’ as pair, ‘hand’ and ‘hands’, ‘little’ and ‘looked’/looking’.
Lastly, I have run the text through the Mallet topic modeler and while don’t know what to make of it yet, the top ten topics proposed by Mallet make fascinating reading, don’t they?
- miss havisham found left day set bed making low love
- made wemmick head great night life light part day dark
- mr pip jaggers pocket mrs young heard wopsle coming question
- boy knew herbert dear moment side air began hair father
- time long face home felt give manner half replied person
- back thought house make ll pumblechook herbert thing told days
- joe don mind place table door returned chair hope black
- hand put estella eyes asked stood gentleman sir heart london
- good round hands room fire gave times turned money case
- man looked biddy sister brought held provis sat aged child
At this point the exploration needs to be fueled by some more pointed questions that need answering. That is what will drive the research. Up until now it has been the tools that have been leading the way as I discover what they can do and what buttons to push to make them do it.