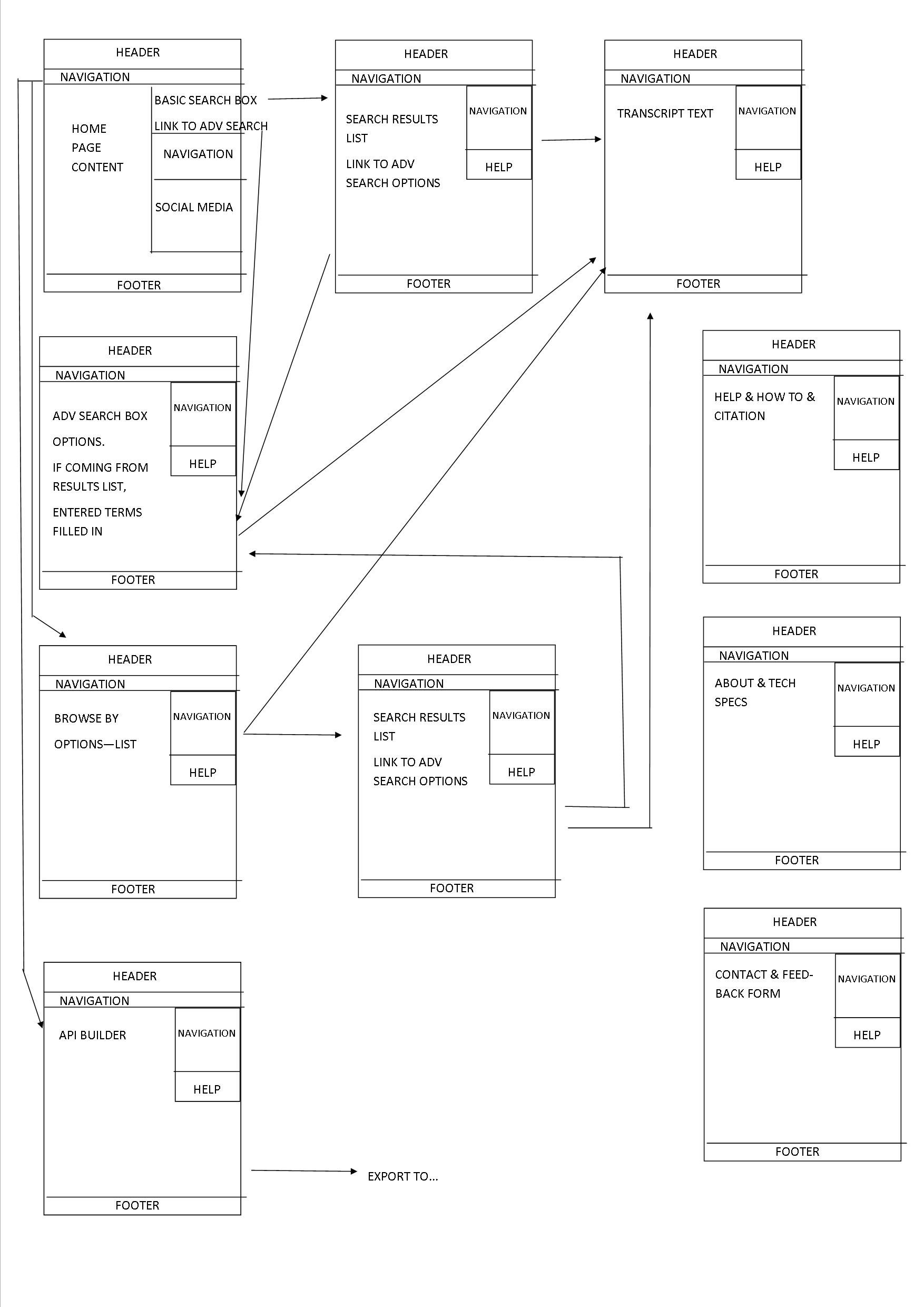
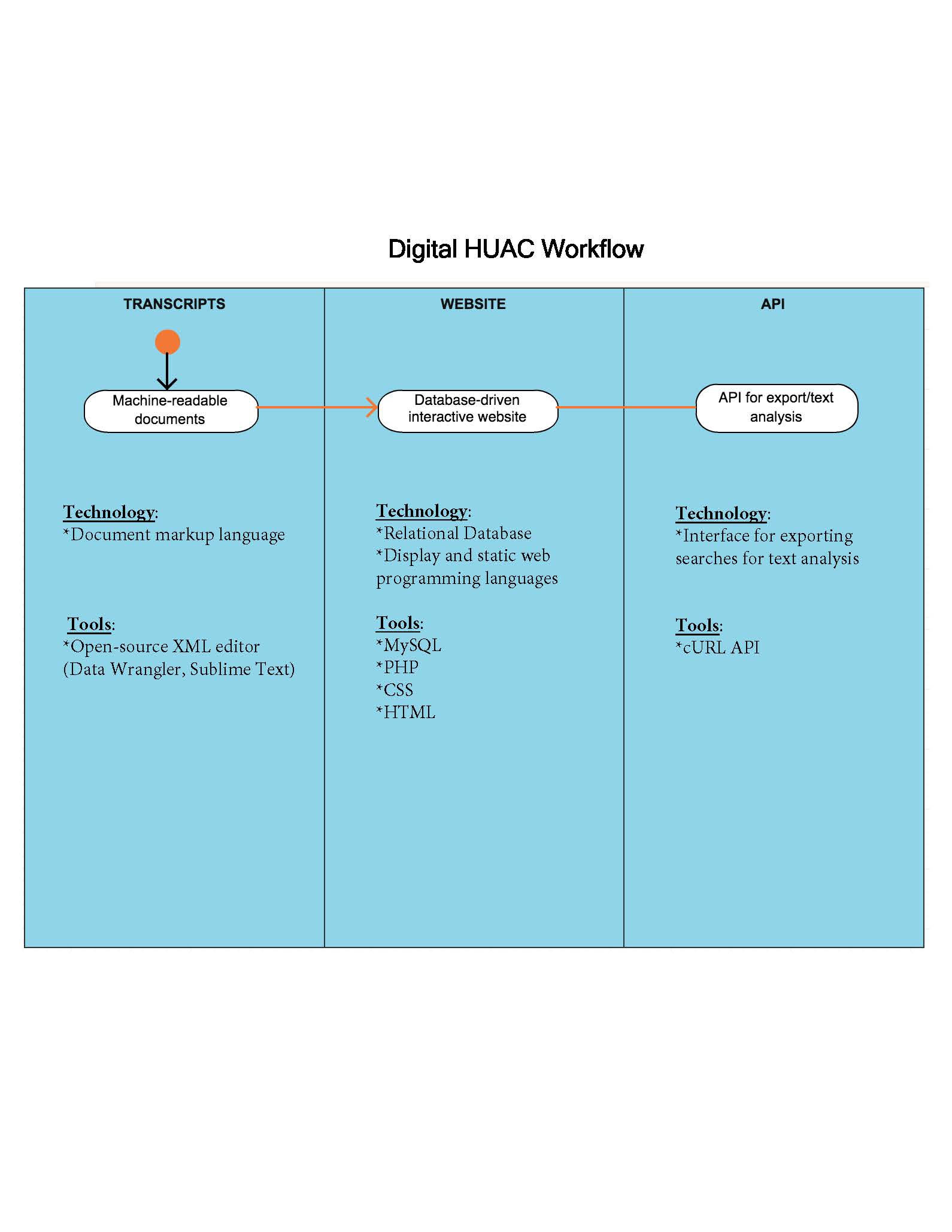
DigitalHUAC project update
Search Form Update
After finalizing the taxonomy with our historian experts, we created a public project on DocumentCloud, where we uploaded the five sample testimonies. For each testimony, we input key value pairs based on our taxonomy.
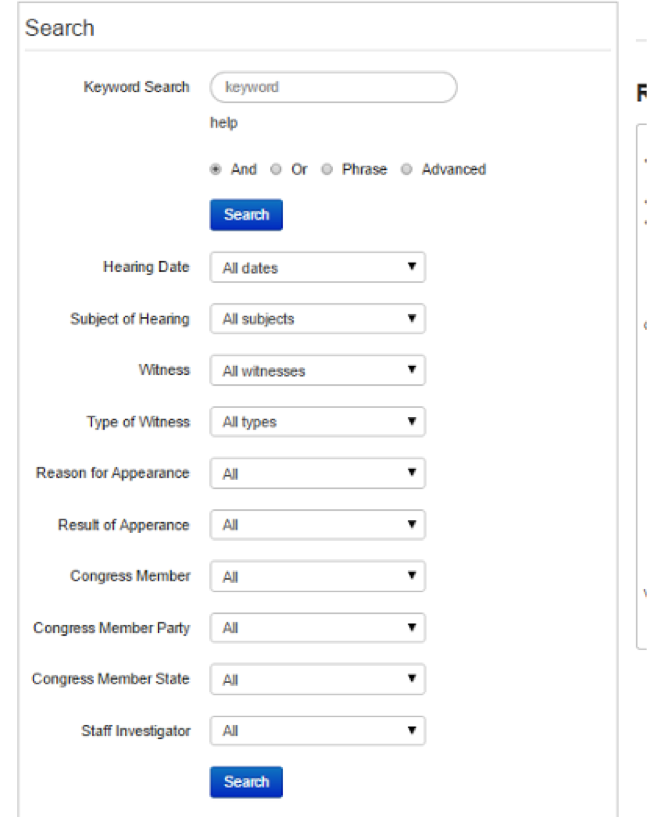
We are still working on the script that will talk to the DocumentCloud API. In the meanwhile, we started working on a search form with HTML only. After making some very basic search forms, we came across a form builder for Bootstrap which allowed us to add more search options very easily. The form builder also provided the html, which we pasted into our test website.
Below is a screenshot:
API Script (Form Action) Update
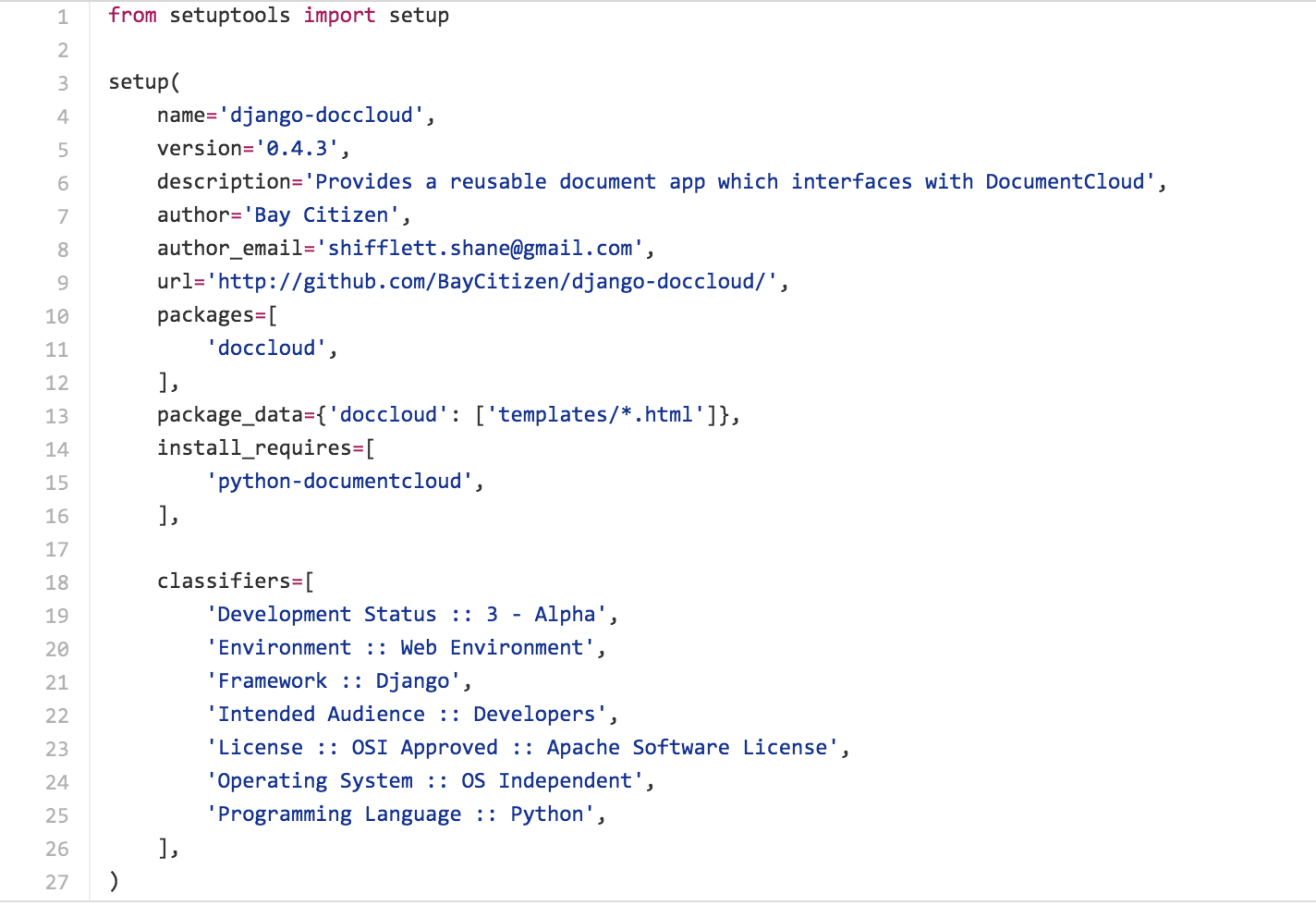
Working with DocumentCloud, we found a) an app that allows users to work with DocumentCloud-documents through a (Django-powered) CMS (built by The Bay Citizen):
https://www.baycitizen.org/blogs/sandbox/djangodocumentcloud-integration-theres/
https://github.com/BayCitizen/django-doccloud
And b) a Python wrapper built for the DocumentCloud API:
https://github.com/datadesk/python-documentcloud
We looked at other documentation that explains how to post html form values into Python script (e.g., http://stackoverflow.com/questions/15965646/posting-html-form-values-to-python-script)
But are currently working with the Python API wrapper, which required downloading a more recent version of Python, with Pip installed, and then installing the python-documentcloud library:
Though the initial attempt(s) return the following:
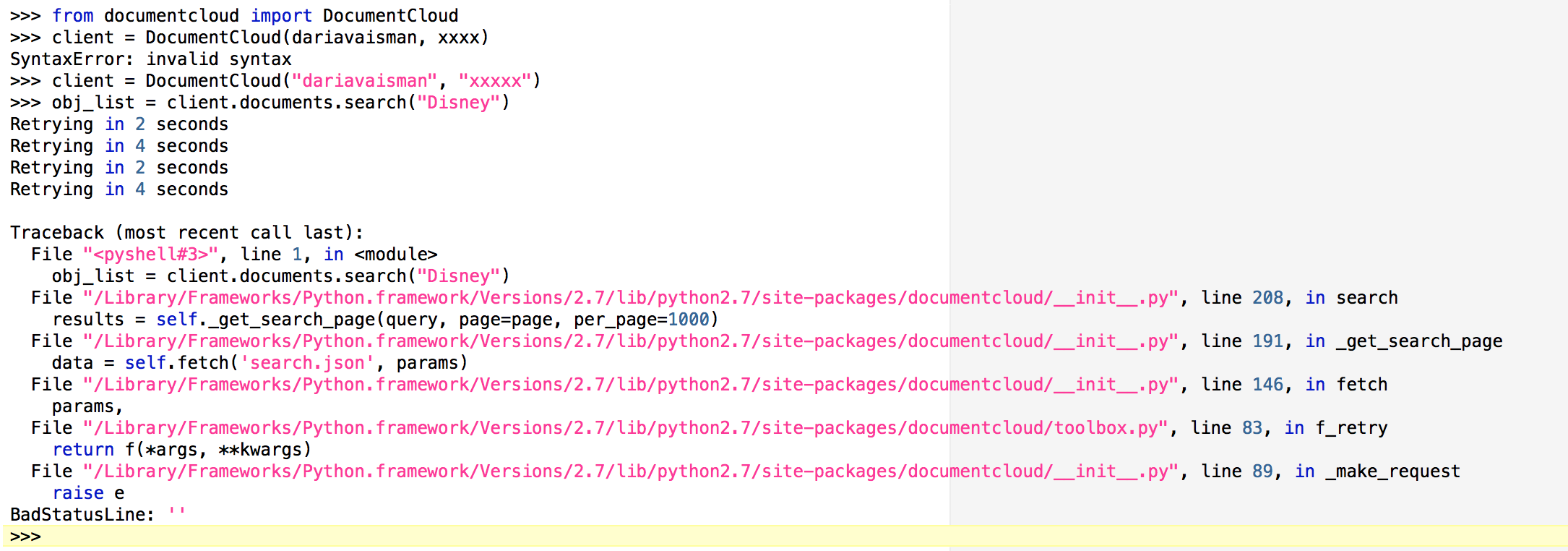
We are continuing with the following Python-documentcloud tutorial:
http://python-documentcloud.readthedocs.org/en/latest/index.html#
https://media.readthedocs.org/pdf/python-documentcloud/latest/python-documentcloud.pdf
In order to be able to extract text from the HUAC PDFs uploaded in DocumentCloud and return the excerpted text to the user:
http://python-documentcloud.readthedocs.org/en/latest/documents.html
And are meanwhile also playing with getting input from a browser via:
-Web forms in Django:
https://docs.djangoproject.com/en/1.7/topics/forms/
-And by using GET/POST methods inside a Python class index:
http://learnpythonthehardway.org/book/ex51.html