This week we’ve been working on our presentation and also fine-tuning narrative elements that will go into our paper. We’re thrilled to be at this stage and are looking forward to Tuesday and sharing in our classmates’ presentations.
Author Archives: Christopher Meatto
DHUAC Update
This week, we’re polishing up our website and writing content for our presentation & paper. We are thinking about how to best showcase the work we have done and how to demonstrate the need for and usefulness of a full scale project. So we’re working on plans for next steps. In a way, thinking about the future helps us reflect on where we are and how we got here, which is useful as part of the praxis element of this project.
As part of this process, we’ve been asking around about HUAC testimonies–to see if we can figure out how many there are out there and where they might all be. Turns out, no one actually seems to know. The Wilson Center and John Jay Library said contact NYPL. NYPL has some stuff, but were not able to give us more than links to their holdings. LoC said contact NARA. NARA said, essentially, it is impossible to know, and in addition to whatever is published and in the world, they also have many boxes of closed executive hearings that are only barely indexed. What we do know is there is no one place where all the testimonies are, and certainly not online and not searchable. It’s sort of baffling that this is the case–one’s mind goes immediately to all of the other incomplete, sub-optimal, or dark archives containing important info that must be out there–though this certainly reinforces the value of our project.
Speaking of search, we’ve got a fancy new search interface. You can check it out and let us know what you think of it. o_O
DigitalHUAC Project Update
We’re presenting this week, so we don’t want to give away too much in this post. In short, however, this week was taxing, productive, gratifying, and exciting—in that order.
After deciding strong encouragement to use Document Cloud (DC) as our database and corpus warehouse, we spent the last few weeks working out how our site would talk to the DC API. No easy thing. What language would be used? How would the syntax work? Wrappers? Formatters? JSON? Above all, what are the relationships between the project’s front- and back-ends, and how does each programming decision/requirement bear these out? This involved much due diligence and scaling of learning curves. No matter: our team is made up of furious warriors, eager to storm the scene. We eat learning curves for breakfast and then throw the dishes out the damn window.
After being advised to lean on PHP (or, as we call it on conference calls, “Playas Hatin’ Python”) for our scripting needs, Daria spent the week shifting her programming language focus. This meant tying together guides and help from a number of sources—our professors, online learning hubs, GC Digital Fellows, outside gurus—drafting code, and testing it out with the rest of the group weighing in and helping troubleshoot. Our main focus this week was on connecting the search form that Juliana and Sarah put together earlier with our DC documents. We needed to be able to run a simple search—at the very least, to have a search form lead to a URL that would display the action that had just been carried out. This, we are happy to report, we have done.
Going back to the point about how the front- and back-ends interact, we also thought this week about what our search results pages would look like. This is of course important from a user experience aspect in terms of display and site navigability: indeed, part of the mission of the project is to organize scattered materials and make transparent an episode from American History shrouded in misinformation and melodrama. But there are just as many meaningful development calls as there are design decisions, and the further we get into the project, the better sense we’re getting for how these two are inextricably linked. We’ll talk more about this on Tuesday, but it’s nice to be at a point where we can think holistically about development and design. In a sense, this is where we started the project; the difference is that now we’re zeroing in on functionality, whereas at the beginning, we thought in terms of concepts.
Also, we received our Reclaim Hosting server space from Tim Owens and are now live on digitalhuac.com. We have yet to install Git on this server, so we are left to update our site like geezers: GitHub > Local Download > Filezilla. We hope to fix this soon and step up our command line game.
Digital HUAC: MVP Post
Over the course of this project so far, and in relation to the feedback that we’ve been receiving, we have scaled up and down our goals and expectations. It has been both humbling and empowering to consider everything we can do within the constraints of a single semester project. When asked to brainstorm our minimum viable product (MVP) this week, over a conference call we all agreed on the following:
– a central repository with basic search functionality that stores our corpus of 5 transcripts.
– a database that can be scaled.
What does this mean, and how does it differ from our current project goals?
We are attempting to generate a platform that connects a relational database to a robust search interface and utilizes an API to allow users to extract data. We envision Digital HUAC to be the start of a broader effort to organize HUAC transcripts and allow researchers and educators access to their every character. By allowing advanced searches driven by keywords and categories, we seek to allow users to drill down into the text of the transcripts.
Our MVP focuses on storing the transcripts in a digital environment that returns simple search results: in absence of a robust search mechanism, users would instead receive results indicating, for example, that a sought after term appeared in a given transcript and not much more.
Our MVP must lay out a model for a scalable database. We are still very much figuring out exactly how our database will operate, so it is hard to fully commit to what even a pared-down version of this would look like. But we know that the MVP version must work with plain text files as the input and searchable files as the output.
Generating an MVP has been a useful thought experiment. It has forced us to hone in on the twin narrative and technical theses of this project: essentially, if everything else was stripped away, what must be left standing. For us, this means providing basic search results and a working model of a relational database that, given appropriate time and resources, could be expanded to accommodate a much greater corpus.
#skillset Chris M.
Hi all,
Here are some things that I bring to the table. I got a handle on some of this in my previous career as a digital archivist at a media company, where I helped build, design, and launch a number of archive projects/products, working across *constituencies* and with many *stakeholders* (and have the argot to prove it). Now as a teacher, I like to think that all of my lesson-planning and focus on presenting and conveying meaning also informs my approach to our class. Most days are a logic problem in reverse: I know the ideal outcome of each lesson, but figuring out how to get there sequentially is what it’s all about. This is not unrelated to project development, I think.
Outreach: I recently stepped down as a founding co-editor of a (then) brand-new digital magazine for librarians and archivists. This involved raising awareness, getting in touch with partners and vendors, and generally building the case for why we mattered. Lotsa standard stuff re: social media and putting together announcements and going to meetings, etc.
Project Manager: Through assisting in planning and implementing a number of archive projects, I’ve worked to get different partners and players to talk in common languages, hew to best practices and deadlines, and respect all workflows and schedules. My volunteer editing experience definitely helped with this, too.
Designer/UX: In helping build digital archives, I’ve spent a lot of time thinking about how sites should look, feel, and function. I have some site design experience and feel comfortable with basic publishing platforms. Definitely a skill-set I’m looking to build on.
Developer: Relatively little experience in this area and so I fear that this would be biting off more than I could chew. I have interest in learning alongside my team’s developer, but in the interest of efficiency, I’m probably not the team member best suited for this role.
Also wanted to echo Julia’s support in encouraging all of these great projects, and toss in my support for Daria’s pitch, too, which sounds rad.
Food Viz.
I like to cook—enough that I don’t eat at restaurants or get take-out all that much—and I tend to think about dishes and ingredients and recipes or ad hoc non-recipes often. Usually it’s a form of meditation: on my ride home from school, I’ll space out and start rummaging through our fridge or cupboards, trying different combinations until something clicks. This is typically how dinners start—a sort of mental Tetris or something.
And yet I’m not sure I’ve ever stopped to consider ingredient or dish etymology or terms of art, really, or how food terms relate to cultures more widely. Flavors and inflections, yes–but not what the words themselves tell us. Maybe that’s because cooking and eating seem to me so rooted in the sensory.
So it was interesting, recently, to check out the NYPL’s What’s On the Menu? project, in which the NYPL Rare Books folks are digitizing, transcribing, and sharing the data from their 45,000-deep collection of historical menus. The collection dates back to the 1840s, and claims to be one of the world’s most extensive.
It’s a beautiful, high-functioning digital archive: awesome search functionality, hi-res images, relational data across the board.

Also, the NYPL staff provide weekly .CSV data dumps of the piles and piles of menus they’re wading through, which is where I started with this project. The freely-available spreadsheets are broken out into Dish, Menu, Menu Item, and Menu Page sheets. I stuck with Dish.
As the project architects note, menus aren’t the easiest things to parse: for one thing, they were handwritten for a long time—a problem anyone who’s worked or researched in an archive can identify with—and their data aren’t structured in any uniform way. For help with that effort, NYPL encourages to folks to get involved and help clean the data up.
As I cruised through different weekly .CSV sheets—many of which run to hundreds of thousands of lines—I noticed a variety of trends: certain dishes dropped off of menus completely, others showed up at certain times and remained constant presences, others came and went, etc. I began to wonder about the relationship between the language of restaurant food and the language of our culture at large: which drives the other? Can we observe anything about popular terminology by comparing menus with other cultural measurements?
From the 400-plus thousand lines of a recent spreadsheet, I identified a handful of dishes to examine: consommé, mulligatawny, kippered, mutton, chow mein, and lasagna. Though there was a metric ton of data to mess around with, I wanted to start with a manageable amount and look at change over time over the course of the archive’s holdings. The first four terms appealed as case studies because they seem to me rather archaic; the remaining two because they are dishes typically associated, albeit in modified ways, with national cuisines not native to the US and so might have something compelling to say about the introduction of foreign foods to the New York City restaurant scene. Here I’ll report briefly about consommé and lasagna. Below is a summary of some of my findings.
I searched on Google’s Ngram Viewer to check out the history of consommé in scanned books from the period 1840-2012 (image below). As you can see, there are definite peaks and valleys, notably the 1910s and the late 30s.
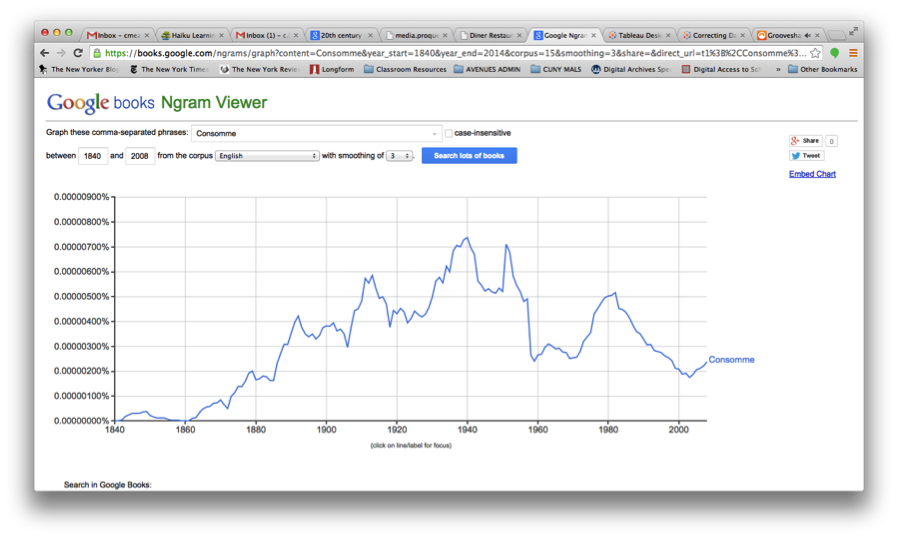
I then went back to the CSV “Dish” sheet and formatted the data to make it more manageable, pulling out all instances of consommé, which ran to over 2400, sorting by date first appeared, date last appeared, and then the number of times this dish appeared in a given year. Then I went to Tableau—with Professor Manovich’s voice tsk-tsking me all the while—and started plotting points. (I’d messed around with Gephi and Raw a bit, but found Tableau way user friendly). After some minor tinkering, I succeeded in generating the following:
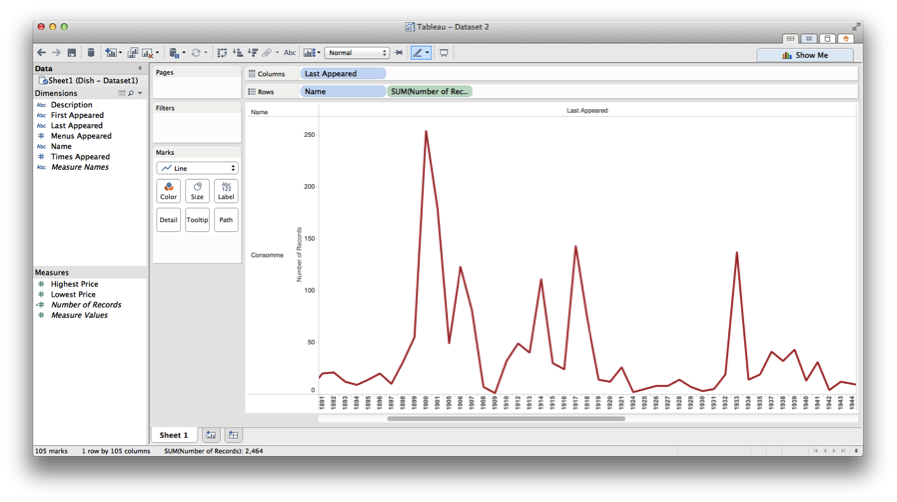
To get this, I used the “Last Appeared” date entries for each dish for column values, and number of occurrences along the rows.
There seems to be some correlation between the two—again, notably in the 1910s—with flickers of coincidence throughout. Does this get me any closer to understanding whether restaurants influence what terms get used beyond their doors? Not sure. But it’s a decent place to start.
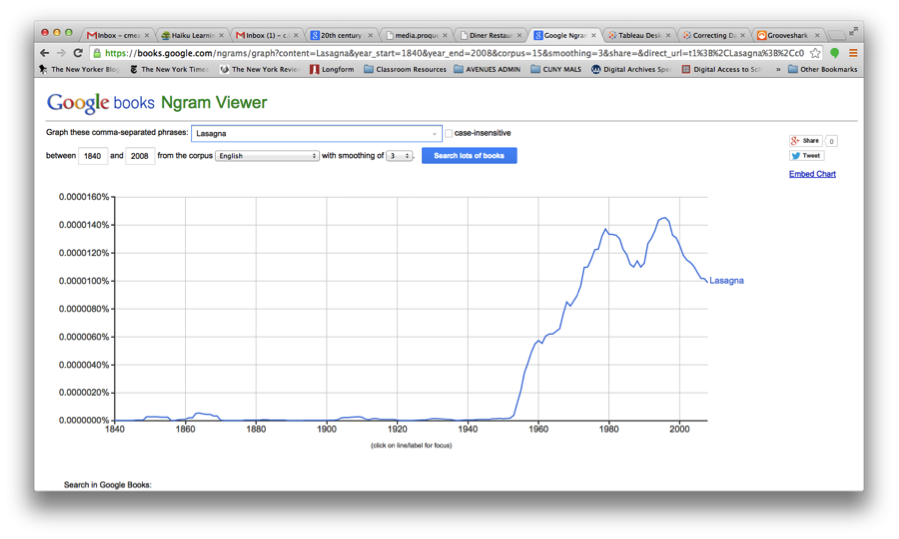
I wanted to look at lasagna because it’s delicious, half of my family tree settled as Italian immigrants in New York over the course of the last 100 years, and examining incidences of Italian-American food showing up on menus seemed like a cool way to look at how cultures interact. Here’s what Ngram had to say about lasagna for the period in question:
And here’s the Tableau-generated chart of occurrences within the NYPL menu project:
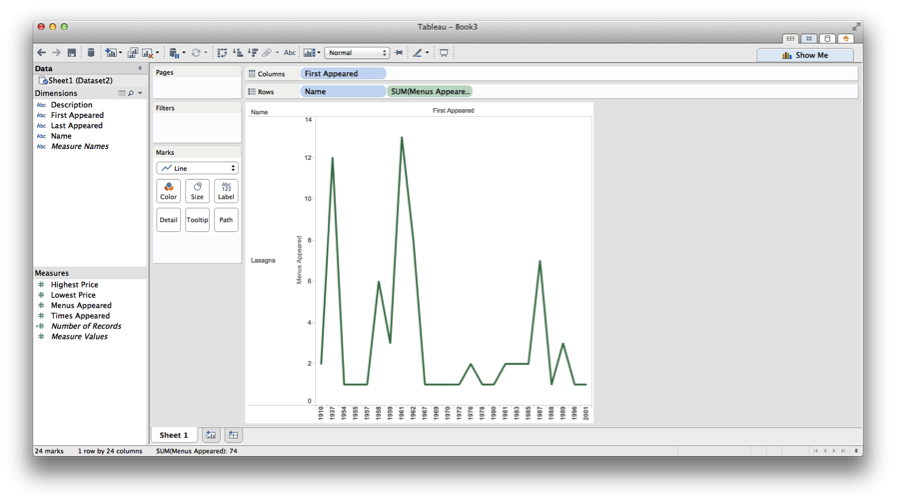
Generally speaking, there are some consistencies here, too: the early 1960s are mostly when this dish starts showing up in restaurants and in Google’s scanned books, and there are matching peaks in the late 1980s.
Since I was looking for possible connections between food language and popular language, I thought to look at the immigration numbers for Italians in the US. The chart below offers some numbers to start with—you can look at this and immediately identify major periods of emigration, the World Wars, the establishment of quotas, and so on. Many, though of course not all, Italian immigrants ended up in New York. According to the 2000 NYC census, for example, about 692,000 New Yorkers claim Italian lineage.
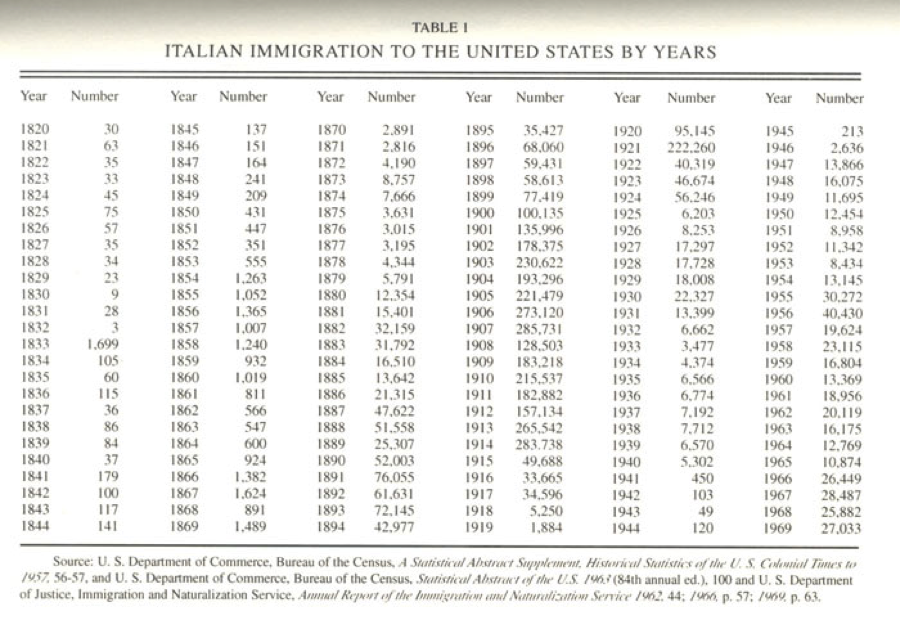
https://www.mtholyoke.edu/~molna22a/classweb/politics/Italianhistory.html
This might be a good starting point for a longer study of food and its relationship between assimilating and/or preserving culture—but I’m not sure any real links are there yet. Clearly there is a relationship between when certain people showed up in the city and how long it took for language they brought with them to enter popular speech and writing.
Both the consommé and lasagna examples point to consistencies re: when terms appeared on restaurant menus and when they appeared in other printed materials. Without a more rigorous analysis, though, it’s hard to pinpoint which form had a leading influence. I could imagine either being the case: an item appears on a menu, gain popularity through its culinary success, and spills out into society at large; alternately, a food term is written about by a certain type of influential writer, and restaurants try to piggy-back on the cultural demand for that dish or ingredient and so begin offering it more and more.
Either way, this was a reasonable way to dive in and play around with some data. Are these the flashiest data visualizations? Erm. But I’d like to work with other tools and programs to get a better handle on data visualization and helping craft stories through such depictions. If I were to repeat or reassess, I would get in touch with NYPL and request access to their API well in advance, working out problems as I went. Plus that would undoubtedly be an easier space to work in, and my computer would thank me for not regularly dropping 500 thousand-line spreadsheets onto its to-do list.
Hypercities, History, and the Classroom
I’m an (aspiring) historian and so the turn in HyperCities to consider topics germane to historical research was a welcome one. I’m also a high school history teacher in a progressive, tech-forward school, and one of the things I try to work with my students on is to treat maps like any other document or source: that is, to identify and scrutinize them as subjective, ideology- and agenda-bearing texts. I’ve been interested in how to incorporate tenets of DH work into my own ongoing research interests as well as my classroom, and since reading HyperCities, things have started to snap into focus.
In particular, Presner’s definition of DH as “help[ing] to expose…epistemologies and world-views, ordering systems and knowledge representations in ways that foreground their incommensurabilities” struck a chord with me in terms of both research and teaching (125). When combined with his assertion that geospatial DH might usher in “an investigation of how modernity is not just a temporal designation (as in Neuzelt but also a practice of cartographic reasoning, spatial representation, and geographic persuasion and control,” there seems to be a newfound urgency to this entire project (64). History is made up of those who have tried to reorder the world in terms of space and time, often violently, and the research potential for thick mapping, geospatial analyses, or otherwise stressing the primacy of geography in one’s work are exciting.
Micki commented in class the other day that space is a place of felt values. This immediately called to mind Timothy Snyder’s incredible book Bloodlands, in which he argues for a geographic interpretation of Soviet and Nazi crimes. In examining mass murder and state destruction in terms of territory, Snyder is able to transcend conventional frameworks (national, political/diplomatic, military, etc.) and focus on what this swath of land meant to the regimes who fought so bitterly over it. To ignore the centrality of geography misses the point entirely: from 1933-1945, about 14 million people were murdered in a very specific location. Why there?
Though Snyder doesn’t take a DH route to get there, there are echoes of Presner’s idea of “geographic persuasion and control” throughout Bloodlands. It helped me think about shifting perspectives and embracing new approaches, since reinforced by HyperCities. Anne Kelly Knowles at Middlebury, and the folks at the Spatial History Project at Stanford, are good examples of researchers and historians working across disciplines to look at old questions in new ways, raise new ones entirely, and keep everything engaging. I’m looking forward to jumping into spatial analyses a bit more, which admittedly has to start with getting up to speed on the programs themselves.
Finally, in terms of my teaching, I’m trying to incorporate some DH tools and methods in line with all of the above. The first step was, during a class on European imperialism in Africa, to show them a pre-colonial map of the continent turned upside-down. That went a pretty long way in terms of helping them think about not accepting geographic representations as objective truths. Next up would be having them mark it up for omissions, biases, and so on. The question becomes: how might I scale thick mapping techniques for the high school classroom? I’m thinking of proposing an elective for next year that might be called “Geography.” It would be a history course, but through the lens of case studies as geographic events: the Great Migration; red-lining in America; the New Deal; colonial African history; the Roman Empire; the World Wars…the list goes on. But they’d all be studied, fundamentally, as events about space.