It’s good to know your strengths.
I’m never going to be a data dude. Thanks to Stephen Real who turned me onto Lynda.com (forwarded from Matt), I watched several tutorials trying to recreate what Micki shared during her workshop on Thursday, Oct. 31st.
But, let me back up a moment. Since acknowledging that I’m probably never going to be a data-dude, it occurs to me that my particular strength is as a communicator. To that end, let me share the last two week’s adventures in tech. I have been to EVERY available workshop except the ones on Thursday evenings when I have a previously scheduled class.
This has amounted to six in-person workshops at GC, one FB page, one WordPress site, three online tutorials and an impulsive registration for a Feminist technology course at Barnard (thank you Kelly for referring the info).
Here is what the last month of data-tech-[E]mmersion have looked like:
B-
I have to run a data project for my DH class.
Have you ever, or do you have data on this:
Compare midwife assisted birth to physician assisted birth in US, and data map it.
I want to see the measurable comparisons of how midwives practice relative to doctors. Please let me know if you have anything, also because I want to use it in my thesis paper.
_
She wrote back and advised against it:
“There is a TON of data on this, and it’s kinda complicated. How are you defining midwife? Nurse-Midwife in-hospital? all midwives? all locations, birth centers, hospitals and homes? How are you controlling for maternal status? Just go take a quick look at the literature and you’ll see. I would not encourage you to include this in the thesis — not in this kind of oversimplistic ‘docs’ vs ‘midwives’ way — as I say, WAY too complicated for that.”
__
I wrote a friend of mine who is a public health nurse at Hunter.
She wrote back:
“Here are some sources. Is it by state or national data you need to map? Do you know Google Scholar search?
Here’s a link to a report published in 2012 re Midwifery Births
Here’s a link to an article comparing births MD vesus CNM
National Vital Statistics Report ***** best resource for raw data
CMS Hospital Compare
https://data.medicare.gov/data/hospital-compare
National Center for Health Statistics Vital Data
http://www.cdc.gov/nchs/data_access/Vitalstatsonline.htm
NYC Dept. of Health Data & Statistics http://www.nyc.gov/html/doh/html/data/data.shtml_”
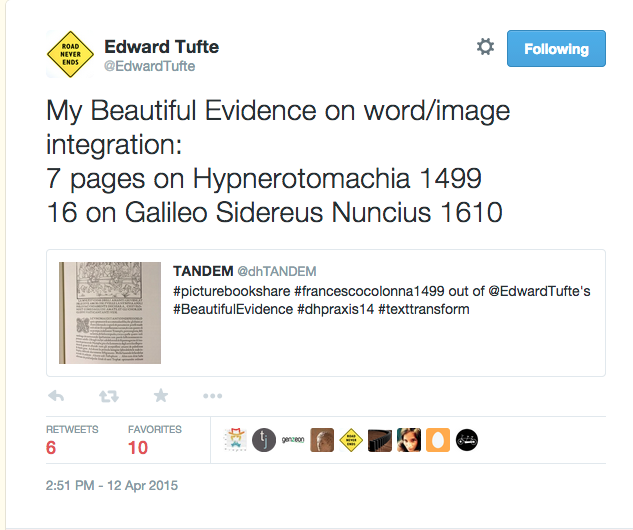
- Thursday, October 30 – Data Visualization, (Micki Kaufman), Library GC; Impressive project and great demo. Again, I wish we could have actually tried to do some of the things Micki demoed.
- Friday, October 31 – Can’t attend the Fellows open hours this week or next week. Wrote Micki to see if she could meet with me at any point during next week for specific questions/answers? Began to export and clean a data set from last year’s academic MOM Conference, thinking it would be interesting to map the geographic locations attendees hailed from.
- Saturday, November 1 – Began the day online taking tutorials. Stephen Real and I met before class on Thursday and he suggested a few things after we discussed how we could create a collaborative project. Today I’m watching Lynda.com videos, but for the tutorials that follow up on where Micki left off on excel documents, I work on a MAC and don’t have a left/right click mouse. So I can’t try a lot of the things they’re demoing. Going to try PDF conversion and scrapping now.
- Thursday, Nov. 6 – Stephen Real and I met up. He and I “played” with some data cleaning stuff. He told me about his “Great Expectations” project. Sounds cool. Spoke with Chris Vitale generously shared some of his tech finds (which people have already been writing about here). Stayed late to talk research ideas with Stephen Brier.
- Friday, Nov. 7 – Technology and Pedagogy Certificate Program at the Library. We talked wordpress, plug-ins, and sever technology.
- Weekend, Nov. 8 – did some research on potential final projects. Explored DH in a Box. I have three ideas. Can’t decide which one to go with. Thinking about creating a survey monkey to ask classmates which idea they like best?
I signed up for “Technologies of Feminism” at Barnard. Starts November 18 and runs for 5 weeks. Here’s what it’s about. Feminism has always been interested in science and technology. Twitter feminists, transgender hormone therapy, and women in STEM are only more recent developments in the long entangled history of tech, science, and gender. And because feminism teaches that technology embodies societal values and that scientific knowledge is culturally situated, it is one of the best intellectual tools for disentangling that history. In this five-week course, we will revisit foundational texts in feminist science studies and contextualize current feminist issues. Hashtag activism and cyberfeminism, feminist coding language and feminized labor, and the eugenic past of reproductive medicine will be among our topics. Readings will include work by Donna Haraway, Maria Fernandez, Lisa Nakamura, Beatriz Preciado and more. Participants of all genders are welcome. No prior knowledge in feminist theory is required.
During the fall 2014 semester, courses similar to this one are taking place across North America in a feminist learning experiment called the Distributed Open Collaborative Course, organized by the international Feminist Technology Network (FemTechNet). As a node in this network, our class will open opportunities for collaboration in online feminist knowledge building—through organizing, content creation, Wikipedia editing, and other means. Together, we will discuss how these technologies might extend the knowledge created in our classroom to audiences and spaces beyond it.
Still haven’t pulled together a comprehensive plan amidst the massive choices available for the data project yet.
WHEW!
I’m en-JOY-ing the journey, but I’m not sure if I can pinpoint a location or product YET. Onward I suppose.