Excitement!
Team TANDEM is working fast and furiously on all fronts. We’ve hit a few snags but all told, we feel like we’ve got a handhold on the mountains we’re climbing. Here’s a brief overview of the ups and downs of the week:
- Our hope we might springboard off Lev’s tool proved somewhat castles in the air. Lev’s feature extractor was coded in a day. When they went to try to run it again later they couldn’t. Lev suggested we use OpenCV instead.
- OpenCV seems to be a massive and constantly shifting morass of dependencies.
- Jojo attended a couple of talks from Franco Moretti and spoke with him afterwards to see if anyone at Stanford was doing anything similar. While he acknowledged the validity of studying text as image, he seems to show no further interest. Bummer, but his loss.
The Details
In development we’ve got a working program for OCR and NLTK (Go Steve!), and we’re making strides in OpenCV (Go Chris!). Lev suggested that we have two different types of picture books for our test corpus — one that’s rich in color, another that’s more gray-scale with more text. These corpus variations will show the range of data values available to future users of TANDEM. Kelly’s working on scanning an initial test corpus now.

We also have our hosting set up with Reclaim thanks to Tim, as well as a forwarding email domain. Go ahead and send us an email to [email protected].
In design/UI/UX Kelly has been working on variations of a brand identity, for color schemes, logo, web design elements… all of it (Go Kelly!).  The UI is primed to go now that we have hosting for TANDEM. Kelly is currently working on identifying the code for the specific UI elements desired, for an “ideal world” situation. The next steps for design/UI/UX are to pick a final brand image, and apply it to all our outreach initiatives.
The UI is primed to go now that we have hosting for TANDEM. Kelly is currently working on identifying the code for the specific UI elements desired, for an “ideal world” situation. The next steps for design/UI/UX are to pick a final brand image, and apply it to all our outreach initiatives.
In outreach, TANDEM had a good meeting with Lev on Wednesday. He seems to think we’re doing something other DHers aren’t quite doing. We’re not yet convinced that it’s not just because it’s crazy hard. Either way, we’re up for it. Otherwise, Jojo has been working it hard (Go Jojo!) on all outreach fronts. This week we received interest from Dr. Bill Gleason at Cotsen Children’s Library at Princeton, where they’re working on ABC book digitization and seem especially interested in our image analysis. This response is proof of relevance in the field.
In regards to social media, we now have a proper twitter handle, which we will admit happened in the middle of last week’s class thanks to some pressure from Digital HUAC already having one. You can follow us @dhTANDEM. More on Twitter: TANDEM had a couple really useful retweets (hurray Alex Gil, massively connected Columbia DHer!) that generated some traffic on our website (jetpack has us at 138 views so far, which is not a ton, but it’s a start!) and has won us some good DH followers — @NYCDH, @trameproject. We’ve transferred #picturebookshare to the @dhTANDEM account, and inviting our followers to participate, as well as use it as a means to suggest additional items for our test corpus.
THE MINIMUM VIABLE PRODUCT (MVP)
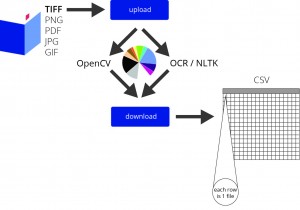
MVP version #1
Because TANDEM is leveraging tools that already exist, one very basic minimum deliverable is that TANDEM makes OCR, NLTK, and OpenCV easy to use. Moreover, if TANDEM itself is not easy to use, there is no inherent advantage in using TANDEM over simply installing the existing tools and running them.
TANDEM as this minimum deliverable would solve the issue of having these tools in a web based environment, relieving users of the laborious headache of installing the component elements. Even after installing the component elements a user would likely have to write code to obtain the required output. TANDEM will shield the user from that need to be a programmer. At this minimum deliverable, TANDEM has not wrapped the three together into a single output.
MVP version #2
A second, more advanced minimum viable product would be to have a website on which a person could upload high resolution TIFF files, press a “run TANDEM” button, and receive a .CSV document containing the core (minimum) output.
The minimum output will consist of six NLTK values (average word length, word count, unique word count, word frequency (excluding stop words), bi-grams and tri-grams) and three image statistics for each input page provided by the user. We hope to expand the range of file types that we can support and to improve the quality of our OCR output, as well as build more elaborate modules for feature detection in in both text and illustrations. However, we contend that demonstrating the comparative values of a couple corpora of picture books will prove that there is relevant information to be found across corpora with heavy image content.
MVP #3
We are shooting for a single featured MVP. A user comes to www.dhTANDEM.com and uploads a folder of image files following the printed instructions on the screen. They are prompted to hit an “analyze” button. After a few moments, a downloadable file is generated containing OCR-ed text, key data points from the OCR-ed text, and key feature descriptors from the overall image. This is purely for an early adopter looking to generate some useful data so that they can continue working on their story and/or data visualization.
Concerns
Overall things are going swimmingly. But of course there are concerns. This weeks concerns range from:
- Can we get the OpenCV to do what we need in the time we have available? This seems to be the element that people really want — the visuality of illustrated print.
- Will be able to scale the project to process the number of pages we would need for users to get the results that would prove TANDEM’s value?
These are, of course, huge questions. But to put it all in perspective: Stephen Zwiebel told Kelly this week that DH Box was held together “by tape” at the time of the final project presentations, and that it has had a lot more time in the past 9 months to become stable. Not to say that we aren’t looking to have a (minimally viable) product come May, but it’s a good feeling to know where other groups were last year. Should we be sharing that widely with the class? Well, we just did. 🙂
THANKS FOR FOLLOWING @dhTANDEM!
a bicycle built by four, for two (text AND image)