Development
On the image processing side of things, Chris has identified the syntax for generating our key values. Now we are working toward stitching the pieces together in a way that makes sense for our output. The extreme minimum of computer vision is accessible via OpenCV and while the possibilities are tantalizing, we have continued to keep a direct focus on the key pieces we need to access for the mvp. TANDEM is still on track.
We have also begun to reevaluate our progress. To do so, we created a new list of dev tasks that range from bite-sized to larger steps so we can visualize how much further we have to go. Steve has been doing a great job of keeping track of progress and using git for version control of his scripts.
In addition we successfully implemented a routine to convert PDF to TXT. Input files are screened by type. If they are JPG, PNG or TIFF, they are passed to Tesseract for OCR processing. If they are PDF they are passed to a PDFMiner routine that extracts the text. In each case the program writes TXT files to “nltk_data/corpora/ocrout_corpus” with a name that matches the first order name of the input file. The latest version of the backend code is here: https://github.com/sreal19/Tandem
Web functionality remains problematic. Most effort this week has been merely trying to get through the Flask tutorial.
To end on a positive note, developmentally, good progress has been made with Text Analysis processing. We are computing the word count and average word length for a single page. The program also creates a complete list of words for each input file. In the very near future work will be completed to create a list of unique words and the count of each. The team must make a decision about whether to strip punctuation from the analysis, since many of the OCR errors are rendered as punctuation.
Design/UI/UX
We’ve been working to identify the ideal UX functionalities for javascript. Most of this was fairly straight-forward, such as giving the user the ability to browse local folders & view a progress bar of the upload/analysis. It has been difficult to locate a script to produce error messages. Searching for anything involving “error” in the name retrieves a different type of request, and “progress” only gets to half of the need.
For instance, we had discussed having the ability to let users identity upload/analysis errors by file, either with a prompt on the final screen or with indicator text in the CSV output. Such a feature will provide the user with the ability to go back and fix the error for 1 file, versus having to comb through the entire corpus and re-uploaded. An example of how this would look would be something this, with text & visual cues that indicate that which file needs review:
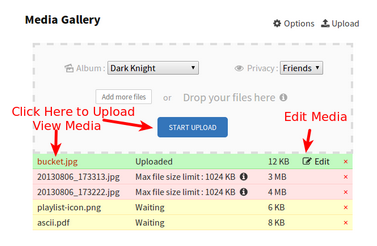
There is some documentation on Javascript progress events and errors, but we need to need to discuss how it could be employed for TANDEM, and whether its necessary for the 0.5 version.
Outreach
Twitter continues to be the primary platform for outreach. While #picturebookshare continues to chime away, we are also now using it to generate research ideas for potential TANDEM users. Fun distant futures for TANDEM might involve the visual trajectories of various aspects of books: visuality of covers or book spines, as well as the visual history of education materials.
Jojo spoke with Carrie Hintz, who has is starting a Childhood Studies track via the English Department, to see if she knew anyone studying illustrated books at the GC. She has no leads yet, but said come the fall she would have a better idea of people interested in TANDEM. Meanwhile, Long LeKhac, an English PhD at Stanford, was giving her a sense of the DH scene there and said he would ask around the DH community beyond Moretti’s lab. Jojo is in the process of devising outreach to text studies experts — Kathleen Fitzpatrick at MLA, Steve Jones — and folks in journalism — Nick Diakopoulos, NICAR and Jonathan Stray, per Amanda Hickman’s suggestion. Keep on keeping on — keep the tweets t(w)eeming.