A lot of you are building out your HTML sites and using Bootstrap to manage the basic CSS. Bootstrap is an “HTML and CSS Framework” which just means that it provides you with a handful of really useful pre-defined CSS classes and definitions that you can use to make a good looking, responsive website. Continue reading
Category Archives: Resources & Links of Interest
You might want to know about … git
If you’ve got a couple of different folks working on the same code base, you need some version control. Emailing files back and forth is not going to work for very long. Trust me. Git is a distributed version control system that allows multiple users to work on the same code and resolve conflicts (like two people editing the same file at the same time.) Even if it is just you, version control is your friend. This used to work, and then you did … something … and now it doesn’t? Roll back to the version that worked.
Git is a free and open protocol. Anyone can implement it. And there are people who will tell you that what makes git great is that it doesn’t depend on a central hub. Which is true. That is pretty cool. It is also more or less irrelevant to you because you are going to use a central hub. Probably github, that’s what most people use.
You might want to know about … SSH
A number of you have been asking questions about running on your Reclaim server directly. The tool you need for that is SSH, or Secure Shell. I used to have a great SSH tip sheet but it has been removed from the internet. We can talk about that later. In the meantime, I cobbled together a not-half-bad recap of my original tip sheet.
Good Questions
As promised (and apologies for delay) my advice on asking good questions. I wanted to edit it so it wasn’t quite so specific to my journalism classes, and I’ll do that. But Stack Overflow is your friend! Use it. Continue reading
Lynda Access
As I mentioned in class, the library does now have full access to Lynda while you’re on campus. From any computer on the GC Campus network, visit the complete list of library databases and find Lynda in the “L”s. You will have to create an account to access videos and the tutorials are only available to students who are using the campus proxy.
As I have shared in the class, I am a social worker by training and am interested in looking at equity in urban education. I also have three children ages 14, 12 and 9, all of which have had to use the internet for homework one time or another this school year. I am fortunate that I am able to afford to have internet access at home.Unfortunately there are many children in New York City schools who are not as fortunate. Selena and I partnered to work on our data visualization project with the intention of learning a few new things to eliminate our phobia for technology. We also were interested in looking at public schools, their locations as they compare to where free wi-fi is located. We both attended the Neatline workshop and thought we would use it for the data visualization project. To our dismay, we could not figure out how to plot the data onto Neatline and decided to go with using CARTODB instead. We decided to take our data visualization project and use it towards a proposal for a free wifi access awareness and social action project. Our hope is to get more free wifi access in low to moderate areas for the purpose of ensuring that all children have access to the tools that will help them succeed academically.
After many hours of troubleshooting, we finally figured it out. We are proud to show you our final product:
https://smw.cartodb.com/viz/e6095f6c-80ec-11e4-9bef-0e9d821ea90d/embed_map
Here we decided to add a Torque feature to make the map more appealing to the eye:
https://smw.cartodb.com/tables/nyc_free_public_wifi_12052014/public/map
Since some of you may be interested in using Neatline I added a link whereas David McClure gave us step by step instructions on how to to download Neatline as well as in putting data into Neatline. I thought I would share the information for all of you:
Instructions for downloading Omeka + Neatline: (By David McClure)
Have a wonderful rest of the year!
Cindy
Twitter and #Ferguson
Dear all,
In the aftermath of the Ferguson decision, and the much-discussed condemning of social media in McCulloch’s speech, we can see the high stakes of a lot of questions we’ve discussed in this class so far.
Perhaps as a way of opening the conversation, here’s a link that shows tweets on #Ferguson and the temporal “hot spots” that happened around key events. Particularly when live-reporting is occurring online, and I’ve seen a lot of news outlets get facts wrong, Twitter’s communicative power is really being harnessed.
http://reverb.guru/view/744067656528025963
-MC
Where do the ‘others’ fit in?
I’m writing this amidst a whirl of thoughts and tracks. Kathleen Fitzpatrick’s views on authorship and the status of private scholarship are impinging on my decision to write to a paper for the final assignment. On one hand, I am glad I read her while battling the dataset project, on the other, she is making me think where my final paper fits in the evolving landscape of scholarship. I am suddenly not satisfied to leave the paper to seclusion. And I am beginning to see the wisdom of having a blog and our instructors’ encouragement of documenting our ‘play’ with datasets. Even as blogs give ‘voice’, it also seems that the essential output remains writing, which, contrary to my decision to write a paper, I’m not entirely comfortable with. I’m still wondering why thoughts presented in writing alone qualify as scholarship; can’t a painting or music do the same? I know there are brave folk who’ve battled this, Nick Sousanis and his dissertation, written and drawn entirely in comic book format, comes to mind. But none of that is considered mainstream. It seems that exchange and communication can expand when ‘intermedia’ becomes a reality, moving beyond the notion of ‘interdiscipline’? In the light of DH being a challenger of notions, how ‘other’ forms of expression can be included in scholarship is a thought to ponder.
For further reading on unusual dissertation forms, I invite you to browse through the following
http://www.hastac.org/blogs/cathy-davidson/2014/08/28/what-dissertation-new-models-methods-media
http://www.spinweaveandcut.blogspot.com/
Finding Data: Preliminary Questions
Hello, all,
As promised, here’s a link to the “Finding Data” library guide on the Mina Rees Library site. Apologies if someone has posted it already!
http://libguides.gc.cuny.edu/findingdata
The guide was created by the wonderful Margaret Smith, an adjunct librarian at the GC Library who is teaching the workshops on data for social research. There’s one more–Wednesday, 6:30-8:30pm downstairs in the library in one of the computer labs–and I’m sure she’d be happy to have anyone swing by. Check out the Library’s blog for details.
Within this guide, the starting questions that Smith provides, in order to get you thinking of your dataset theoretically as well as practically, are very helpful–and I wish I had them years ago! Here are some highlights, taken directly from the guide (but you should really click through!):
HOW TO FIND DATA:
When searching for data, ask yourself these questions…
Who has an interest in collecting this data?
- If federal/state/local agencies or non-governmental organizations, try locating their website and looking for a section on research or data.
- If social science researchers, try searching ICPSR.
What literature has been written that might reference this data?
- Search a library database or Google Scholar to find articles that may have used the data you’re looking for. Then, consult their bibliographies for the specific name of the data set and who collected it.
HOW TO CONSIDER USING IT:
Is the data…
- From a reliable source? Who collected it and how?
- Available to the public? Will I need to request permission to use it? Are there any terms of use? How do I cite the data?
- In a format I can use for analysis or mapping? Will it require any file conversion or editing before I can use it?
- Comparable to other data I’m using (if any)? What is the unit of analysis? What is the time scale and geography? Will I need to recode any variables?
And another thought that I really loved from her first workshop in this series:
Consider data as an argument.
Since data is social, what factors go into its production? What questions does the data ask? And how do the answers to these questions, as well as the questions above, affect the ways in which that dataset can shed light on your research questions?
All fantastic stuff–looking forward to seeing more of these data inquiries as they pop up on the blog!
(again, all bulleted text is from the “Finding Data” Lib Guide, by Meg Smith, Last Updated Oct. 15 2014. http://libguides.gc.cuny.edu/findingdata)
MC
Easy Exercises & PYTHON Manual
RE: Friday help session offered by the Fellows. Here are a few simple exercises I walked away with. These are super basic and not big-data, but if you’re just getting your feet wet, then at least you can start to “play” (for those of us who are nubies to this).
Internet Time Machine
Distance Machine
Go to this link: Google Ngram
Put in some words for things you want to compare.
Sample:
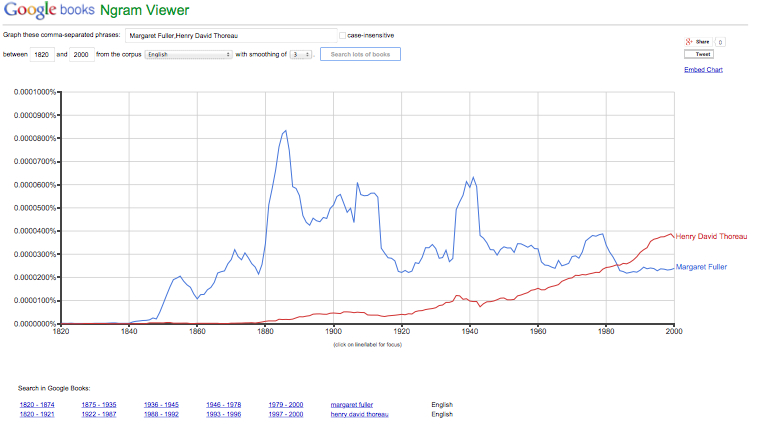
This article also explains how big-data can be practically applied.
How cellphones can predict where Ebola strikes [LINK]
Also attached is a booklet called “PYTHON for Kids” that was recommended. [Python for Kids – A Playful Introduction to Programming]