Hi All,
It’s so exciting to see the progress on this blog; I know so many of us are now able to do things we couldn’t at the beginning of this class, thanks in no small part to all the great workshops. My final project is largely facilitated by the Gephi workshop. In this post I want to share my process in case it’s useful to anyone, but also, crucially, ask for your help to bring it to life. In case this gets long I’ll say now that in the final two weeks of class I hope to ask the praxisers to complete the short (and fun!) exercise of mapping your favorite authors, as well as the people who helped you discover them, in a simple text file. Now into the weeds! (ps I will be more specific when I ask this in earnest).
My goal here is to make the citation process more social, to draw the connections between impactful texts/authors and the friends, partners, mentors, teachers, scholars, family etc. that helped you discover the content. I began with a basic tab delineated text file that looked like this: 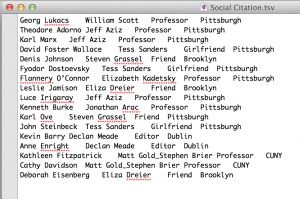
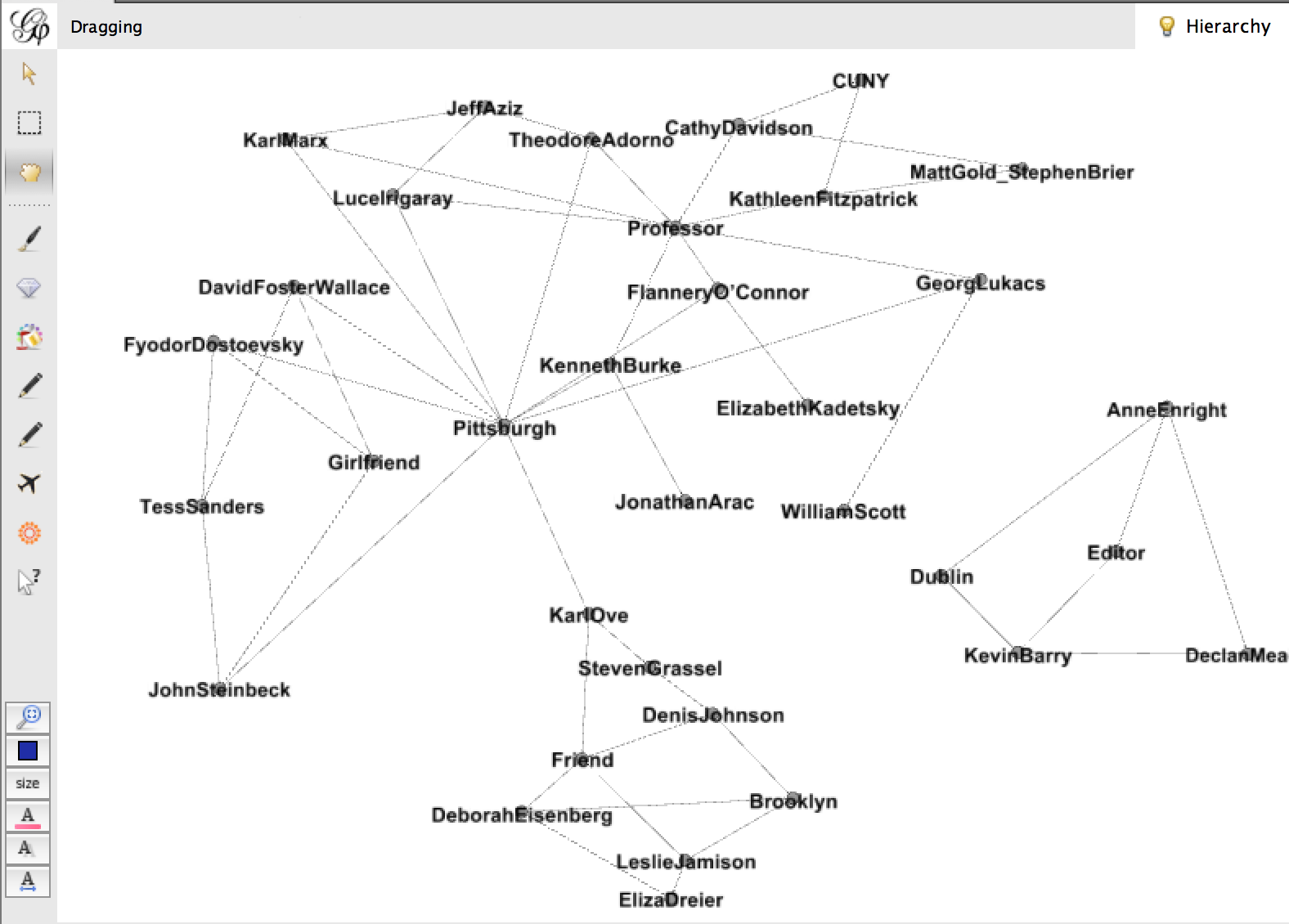
the categories here from right to left are: author, my person, relationship, location. I didn’t get too hung up on the content, just typed what came to mind for maybe 15 minutes. It took a bit of tinkering to figure out how to show this in Gephi, but eventually I got this:
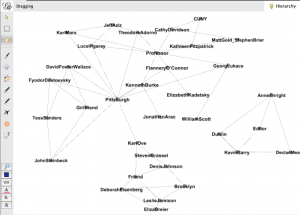
Sorry if this is hard to see, but this is a very messy graph. There are some interesting things going on – the connections are by relationship and location, and they create pockets. Declan Meade is off on his own to the right because he’s the only Dubliner and the only Editor I have. I tried to make this a little more cohesive by changing my data to look like this:
So I got rid of relationship and location, I also made it a one-to-one relationship between everything, where “Me” was connected to each of my people, and each of my people were connected to the work they’d introduced me to. Then the graph changed to this:
This sacrificed some of the nuance of place and relationship, but it gained a simplicity that I think is critical in these visualizations to make sense at a glance.
I’m not sure whether I’d like to add in relationship as a node, or maybe offer it as a hover or something. (color coordinate edges with a key linking them to relationships??) I have more playing to do, and would love feedback. But I think this project gets way more interesting when “Me” is connected to “You”. And so I wonder if folks would be willing to participate in this exercise. I think we can all safely use the three print texts assigned in this course, creating a link between everyone. I’ll finalize the model over the weekend, to have a more developed request for you, but I think the easiest thing would be for me to set up a google doc with everyone’s name on a separate page and ask you to type out the data. It’s important to the project because only YOU know these things – there’s no way to scrape this. Thanks for your consideration, and looking forward to NYPL Labs tomorrow!