Data Mining for a fashion vernacular, #SPREZZATURA
For the data mining project, Tessa and I (we both are in Fashion Studies track) had tried to retrieve some data for a contemporary fashion vernacular, #sprezzatura. Sprezzatura is an Italian term means “a perfect conduct or performance of something (as an artistic endeavor) without apparent effort.” (http://www.merriam-webster.com/dictionary/sprezzatura) In fashion world, this term has been used to describe “effortlessly stylish” people, especially in menswear world. Utilizing API, we wanted to collect the images, the tags (tagged with sprezzatura), the posting dates, the users’ locations, and so on. We picked two social media platforms; Tumblr and Instagram. However, using each platform’s own API console and getting Authentication token and all seemed like a conundrum to us. So I asked my programer friend who works at Comcast a help (He lives in Mountain View, California). He generously walked us through it.
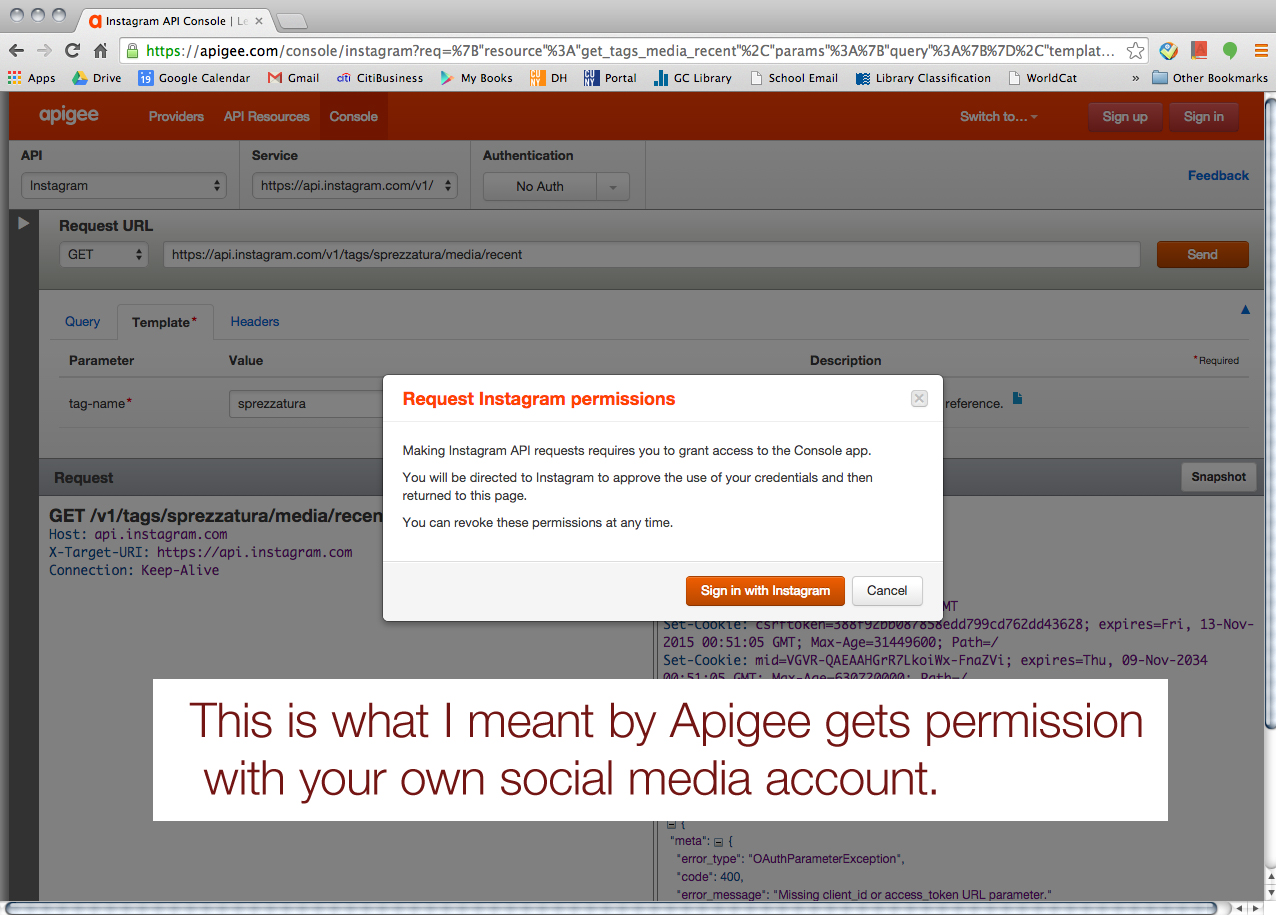
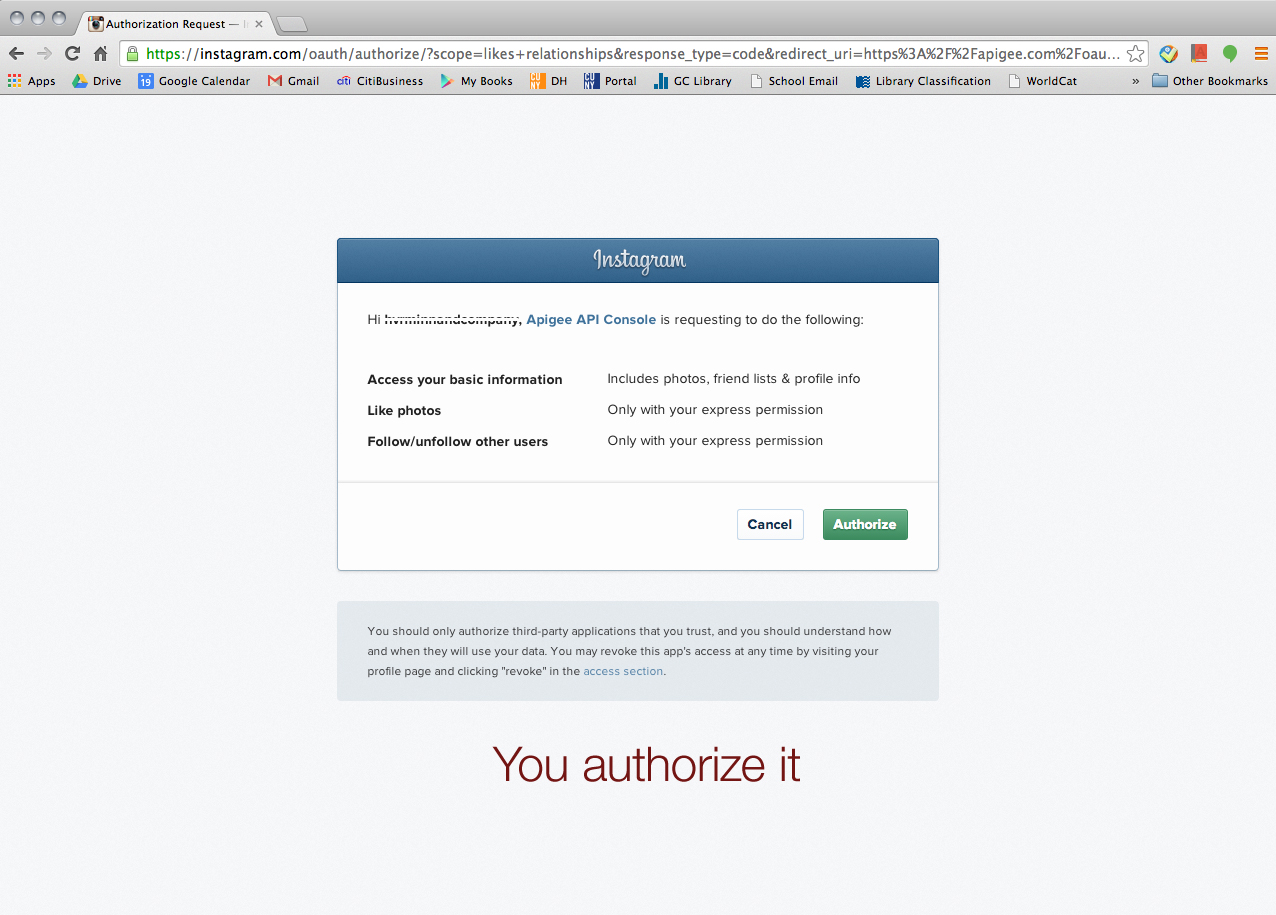
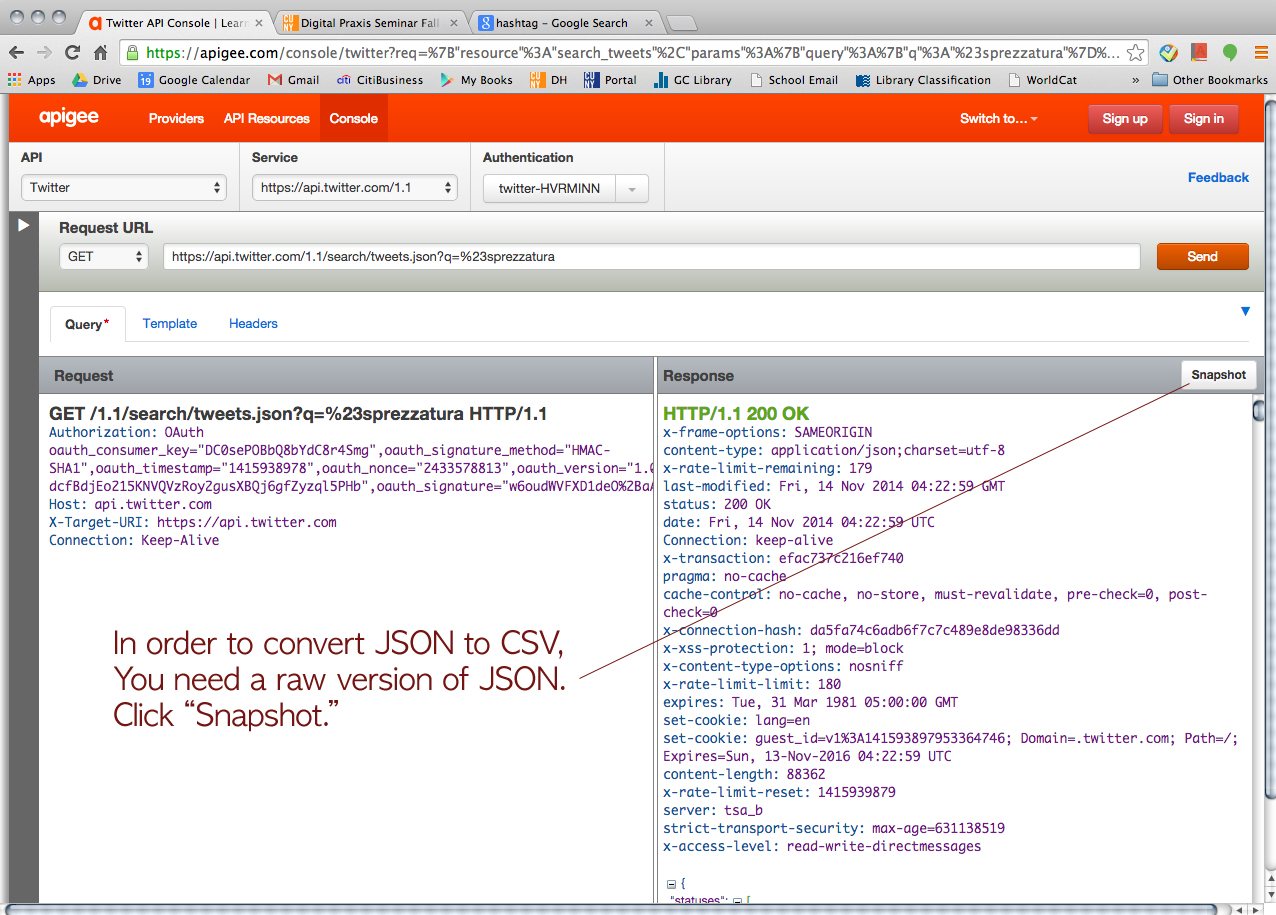
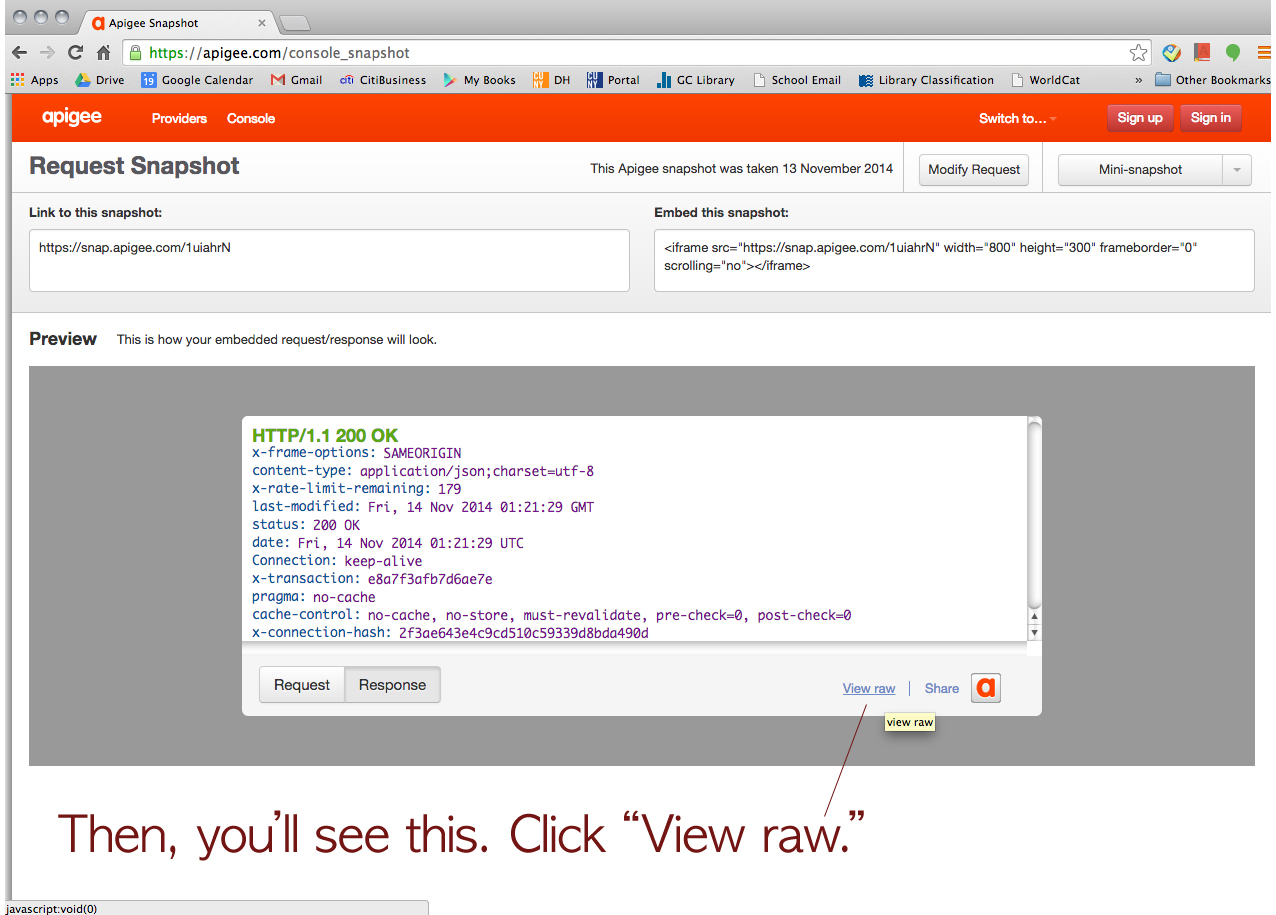
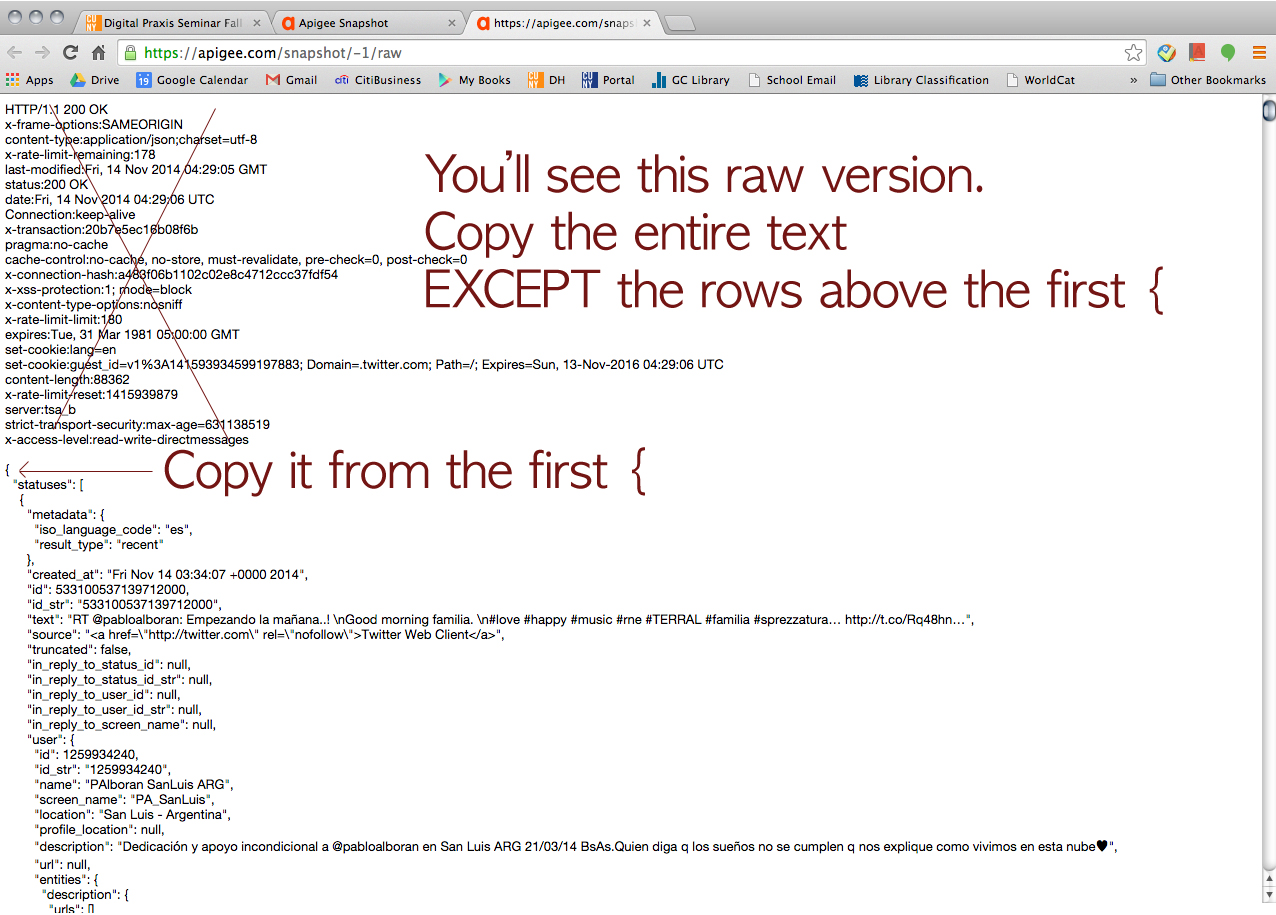
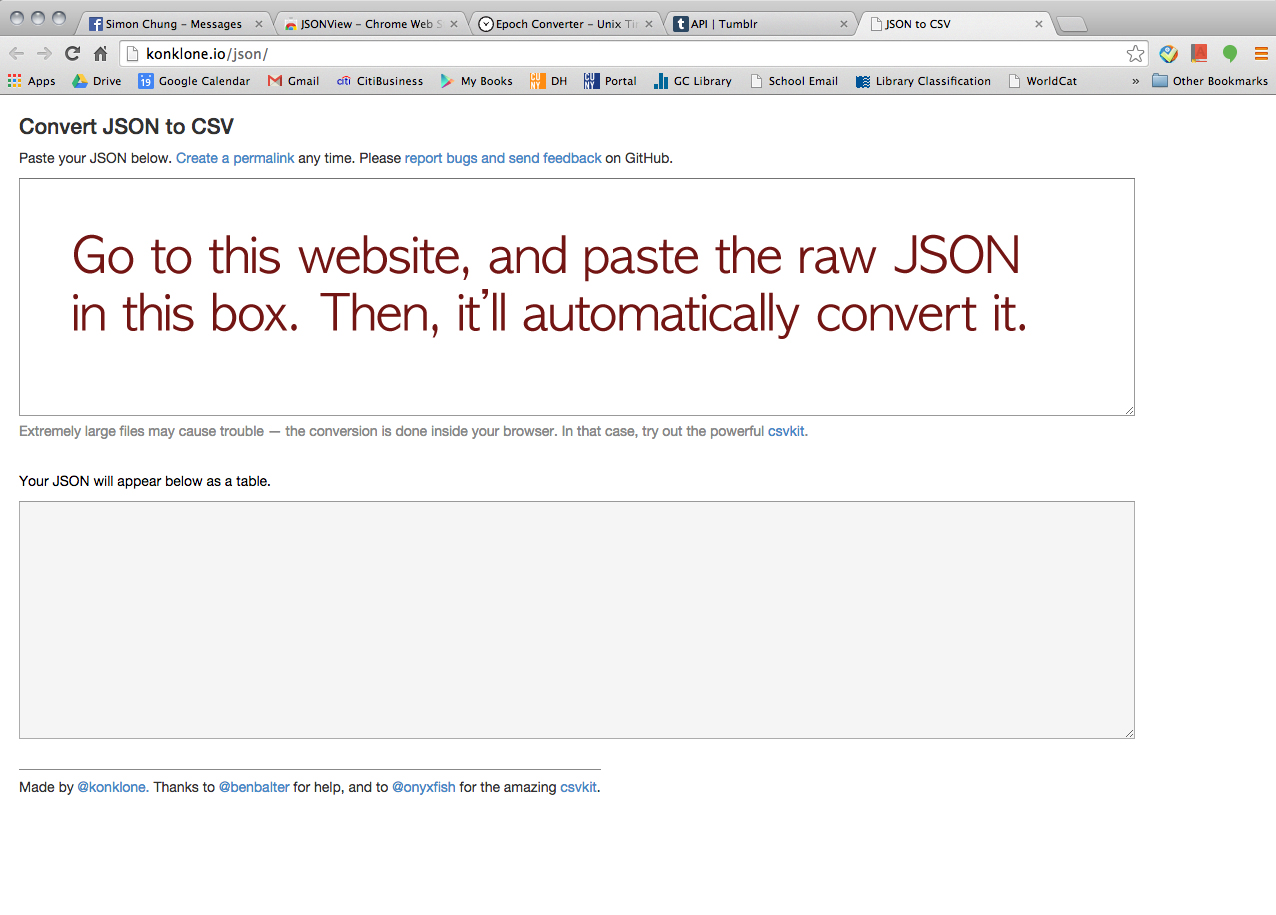
First of all, he strongly suggested us use Apigee website (https://apigee.com), and it’s FREE! It uses your own account for each social media platform for authentication. He said Apigee would be more than good enough for mining simple data like what Tessa and I wanted. I screenshot every step to share it with our classmates. So, here’s how we collected data via Apigee. (We used Google Chrome browser FYI.)
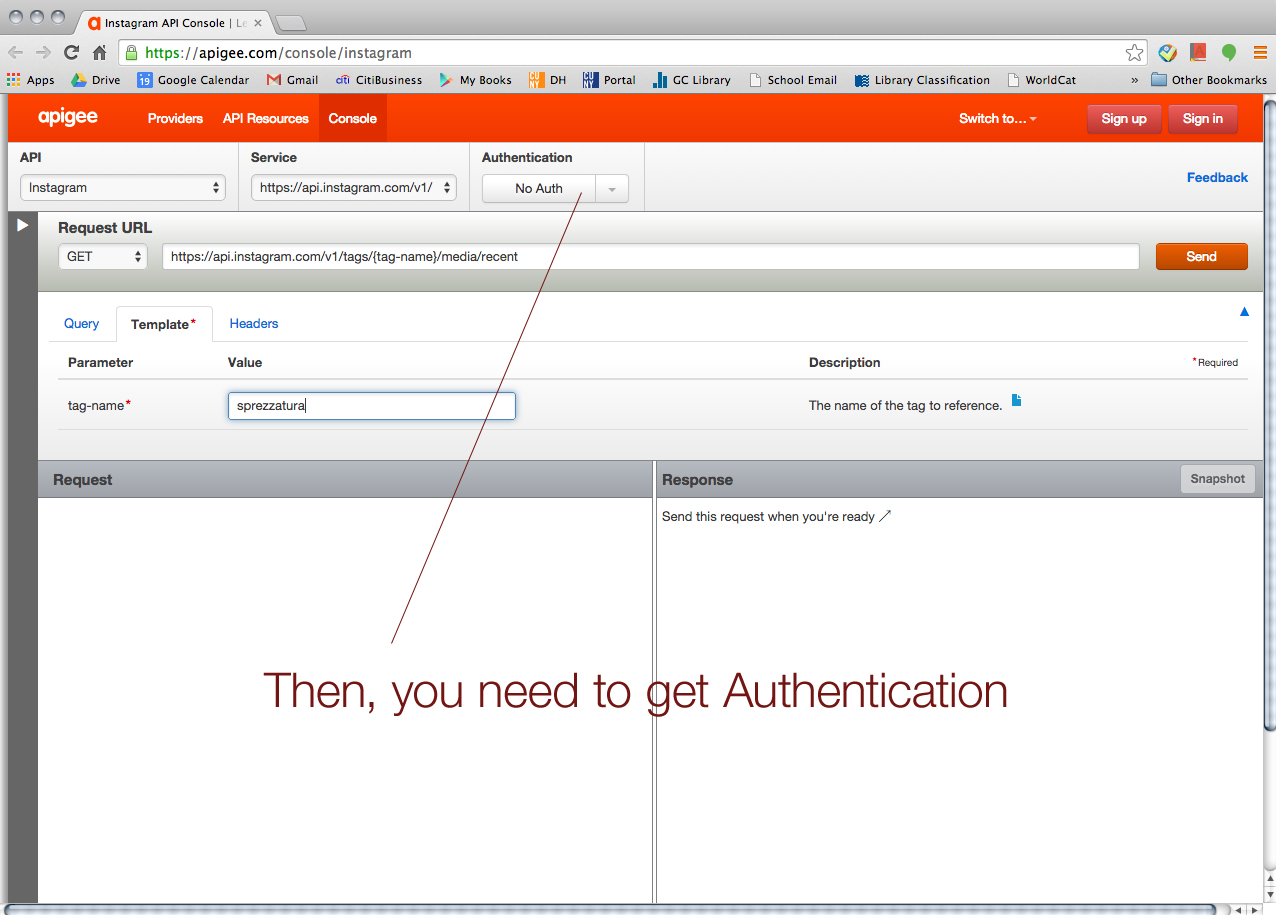
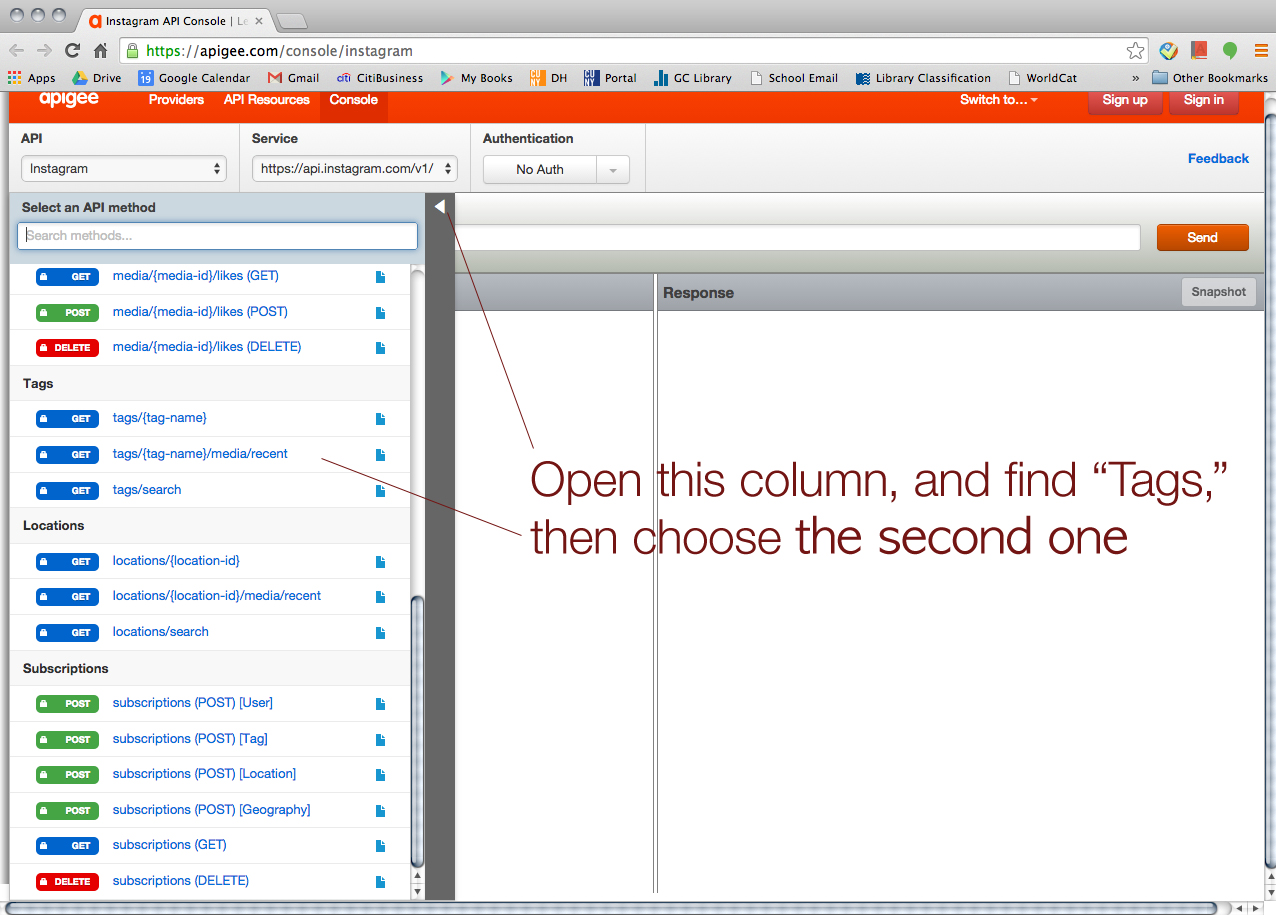
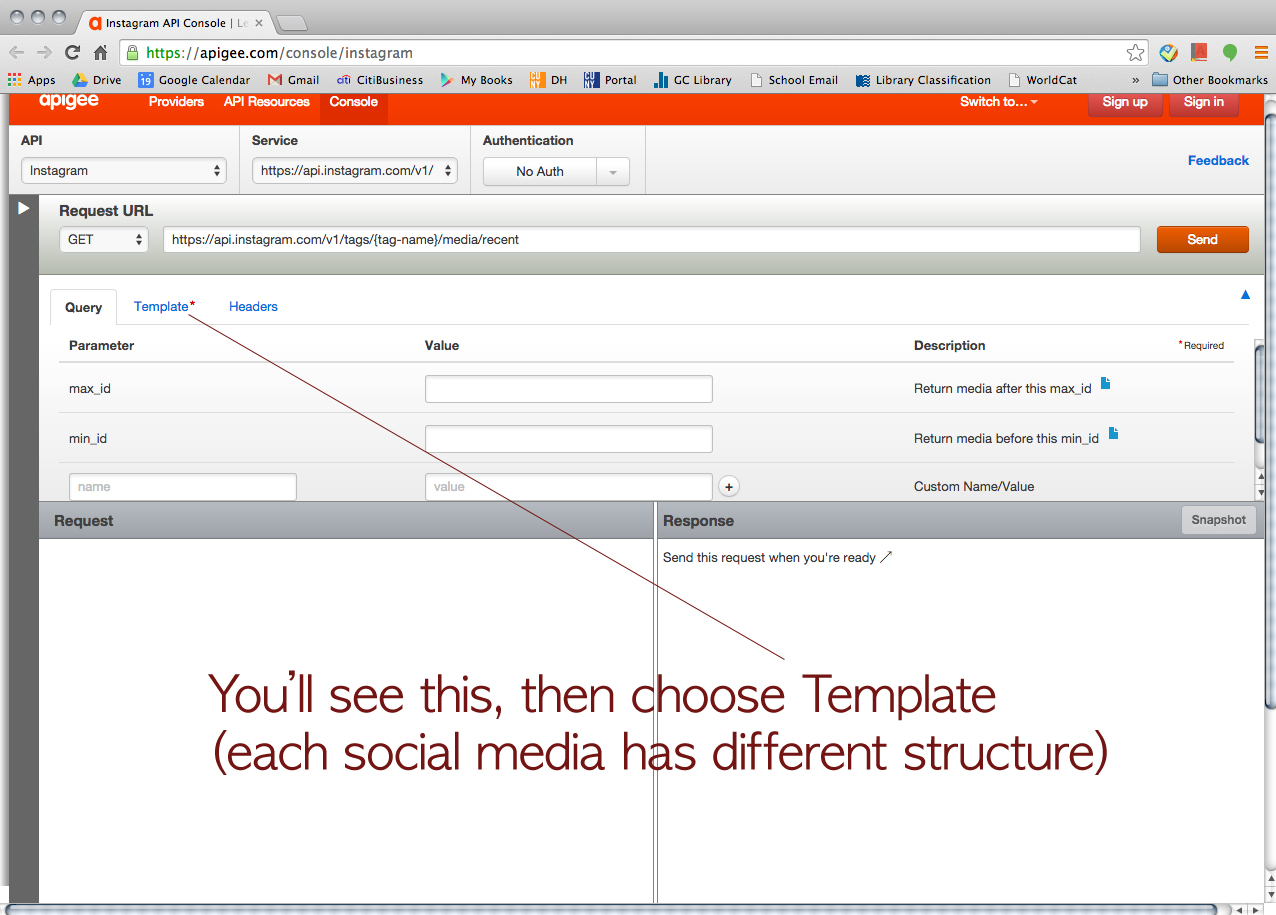
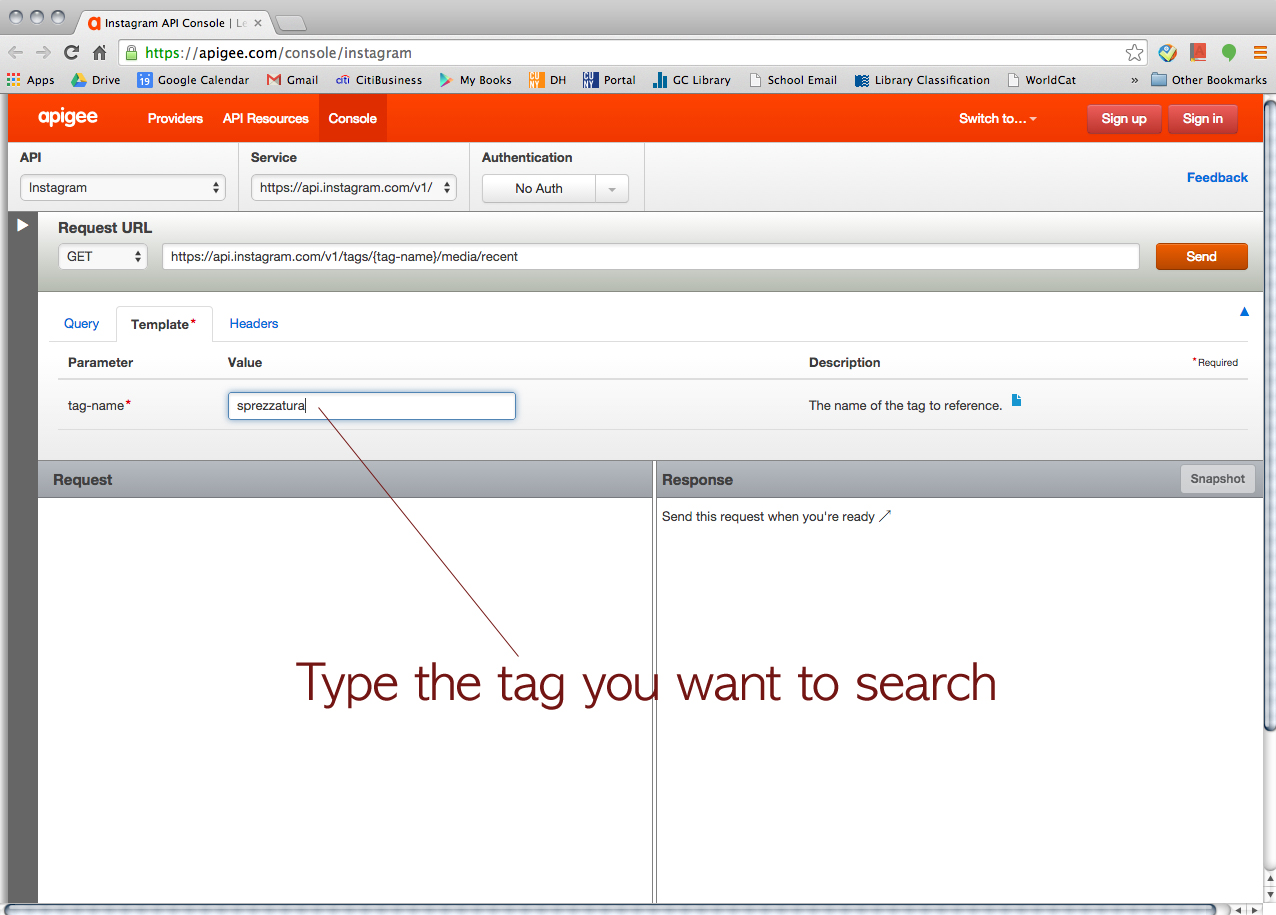
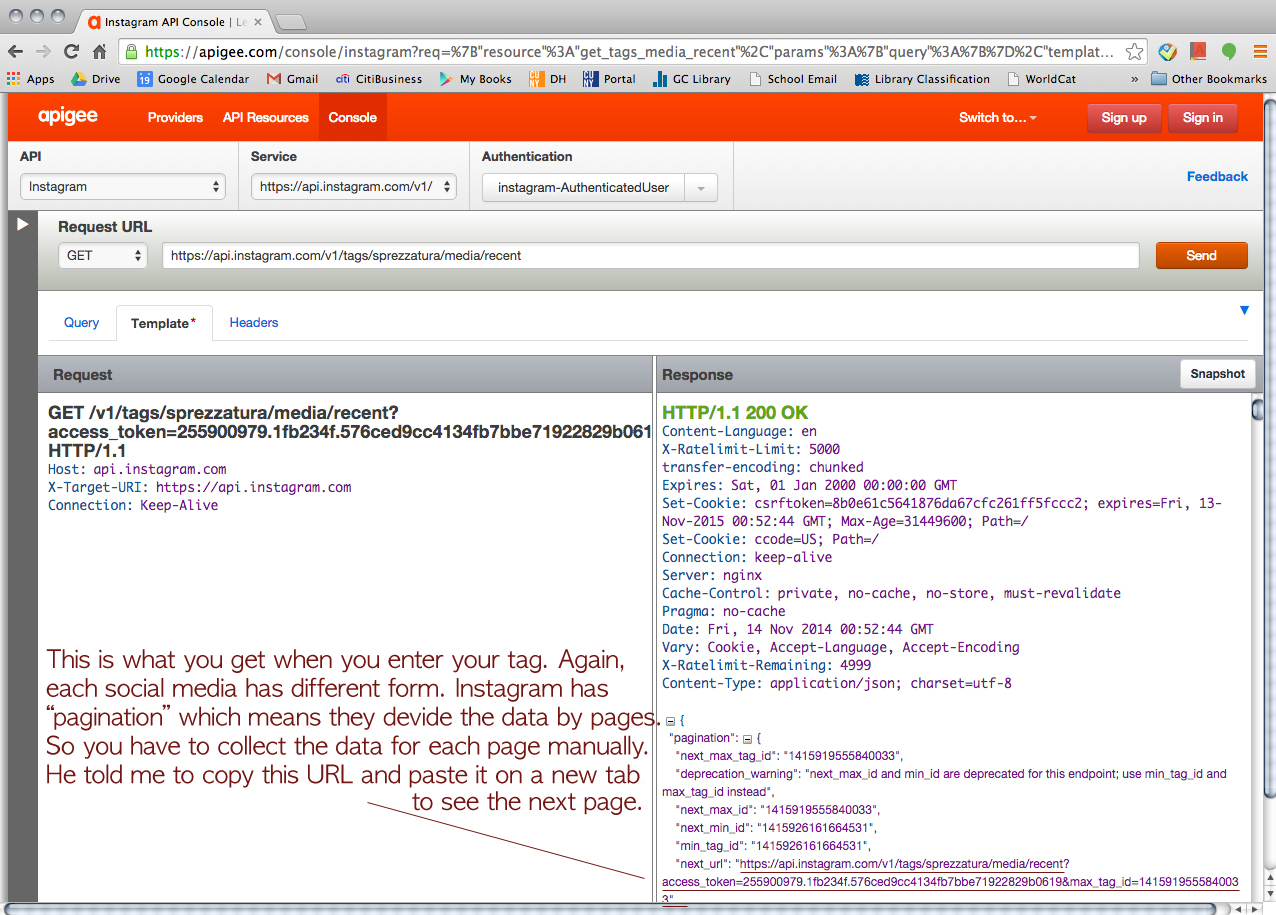
We started with Instagram. > https://apigee.com/console/instagram
Choose “OAuth 2”
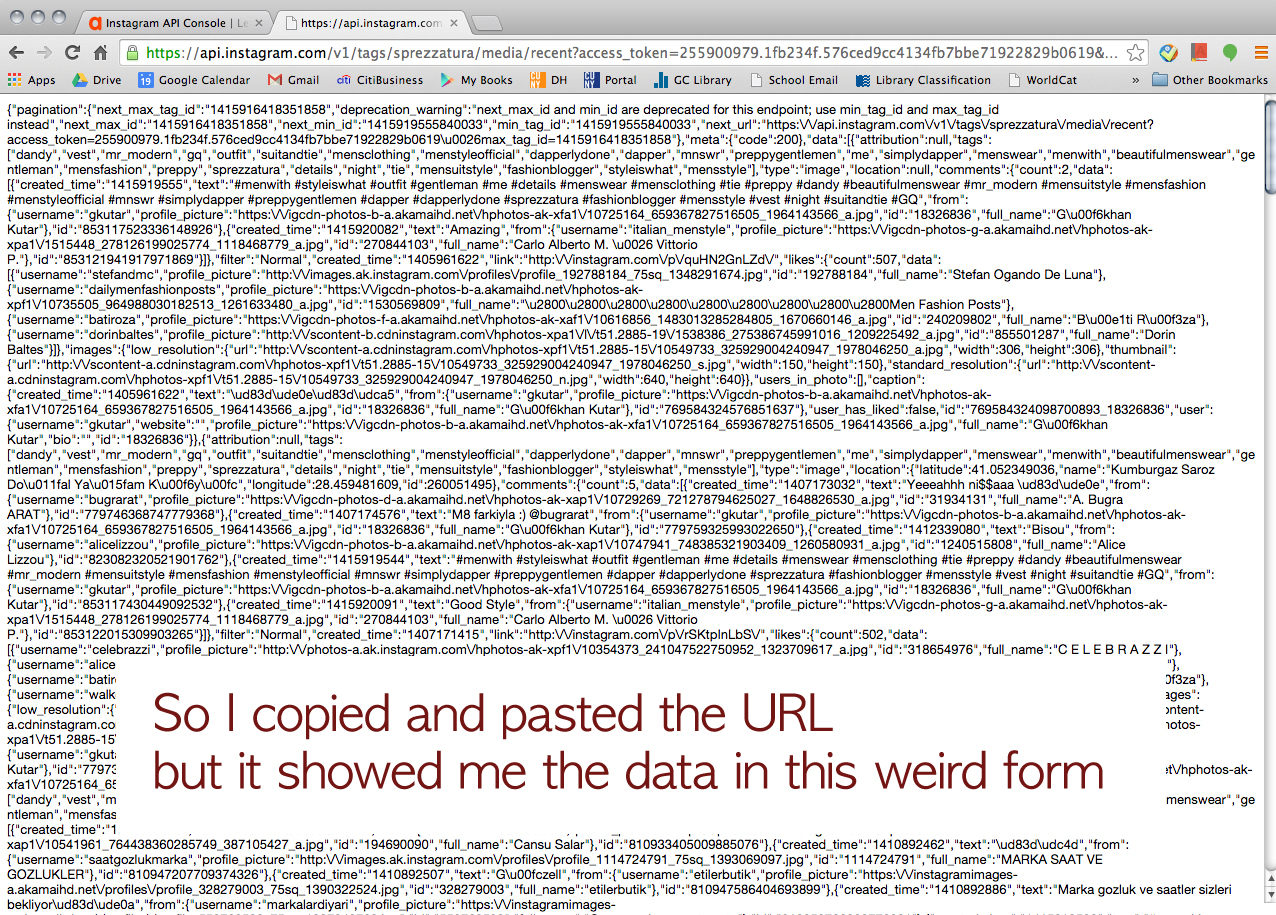
Click this URL > https://chrome.google.com/webstore/detail/jsonview/chklaanhfefbnpoihckbnefhakgolnmc?hl=en
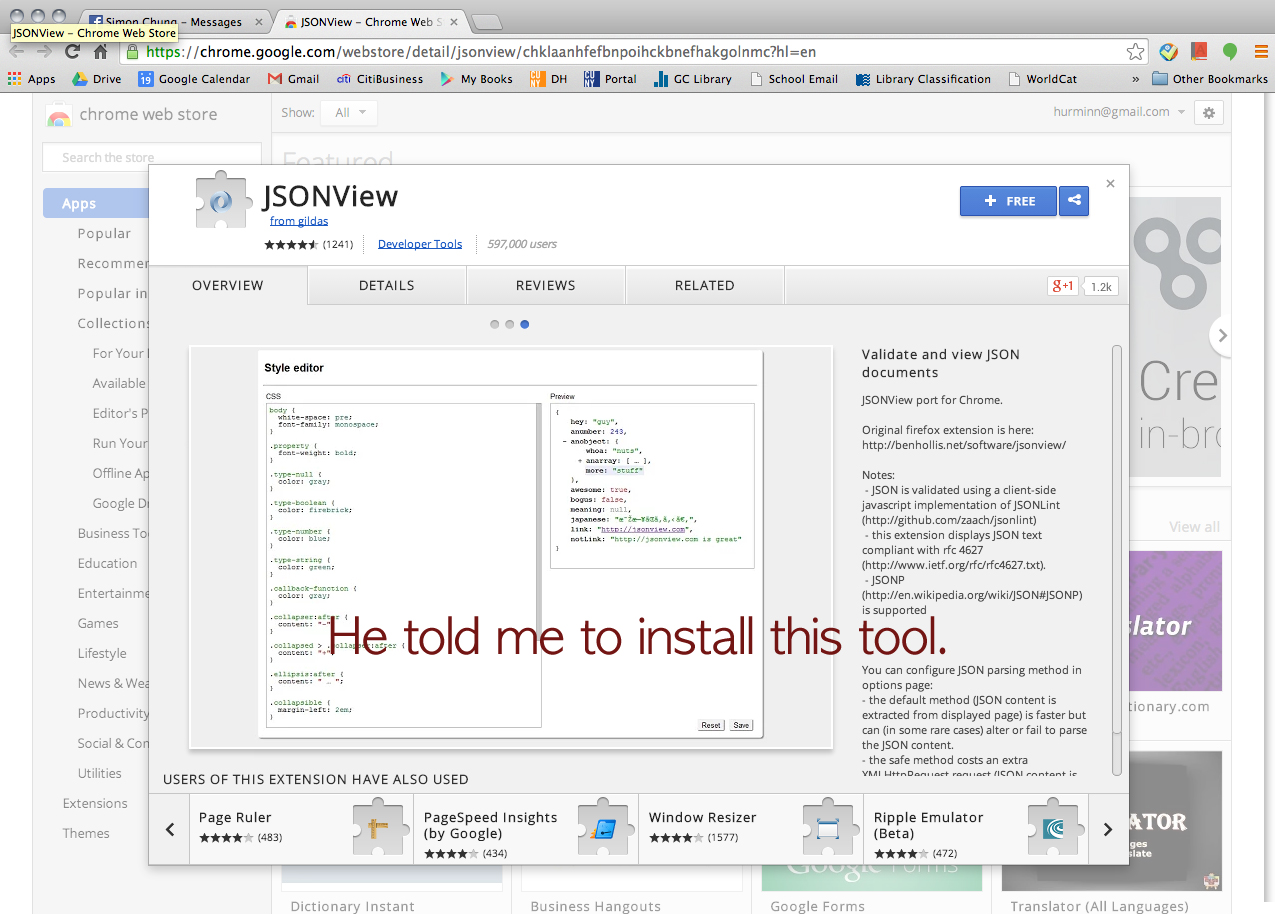
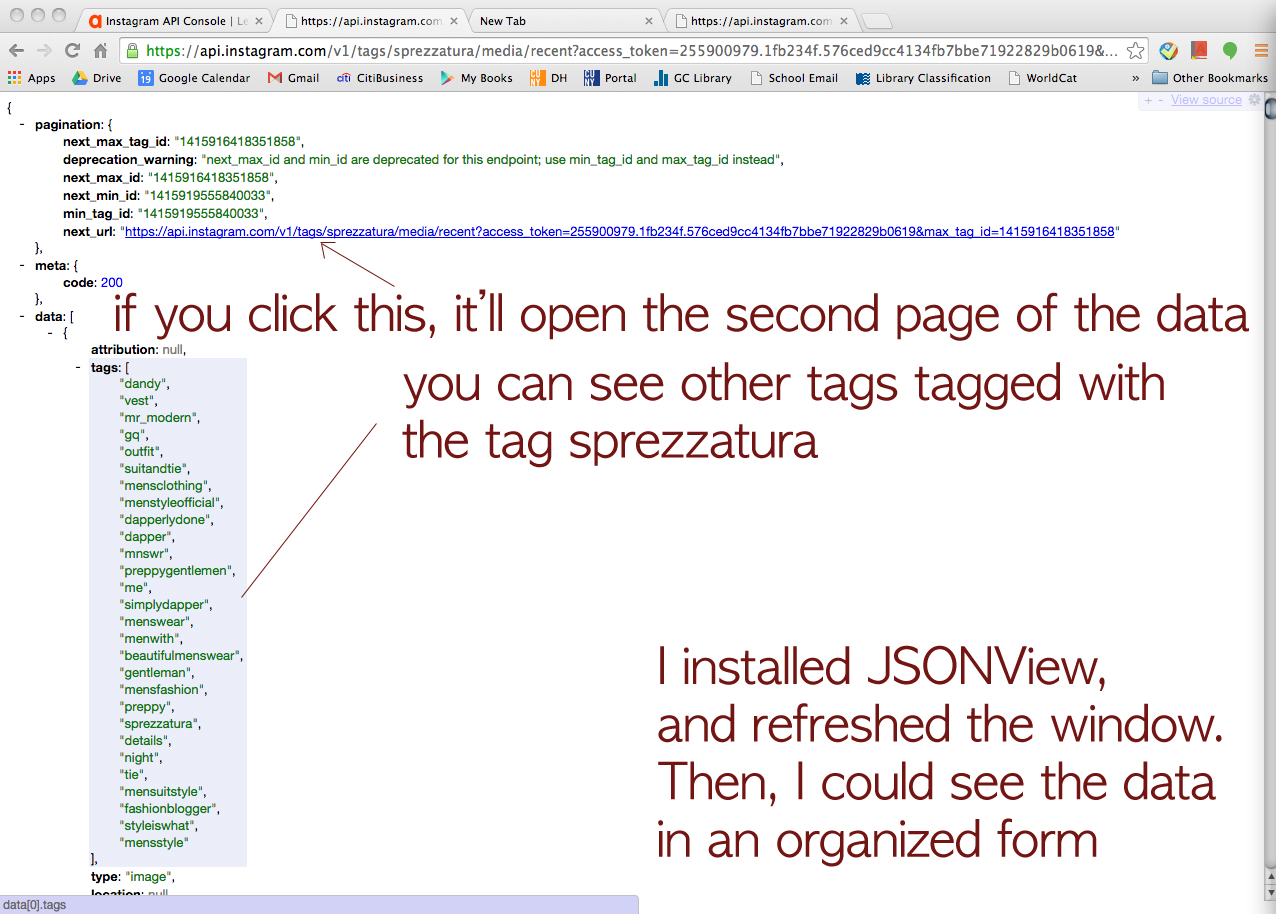
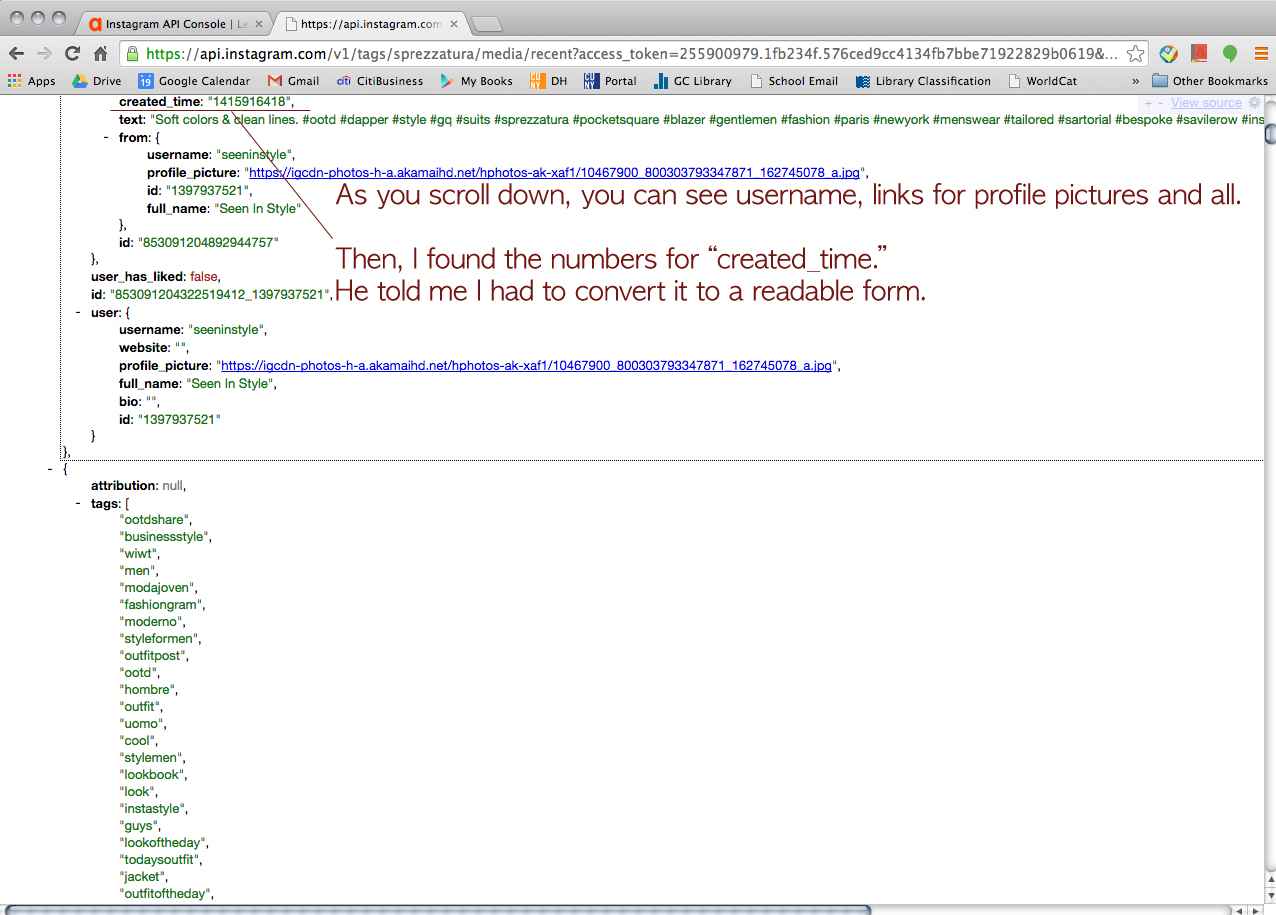
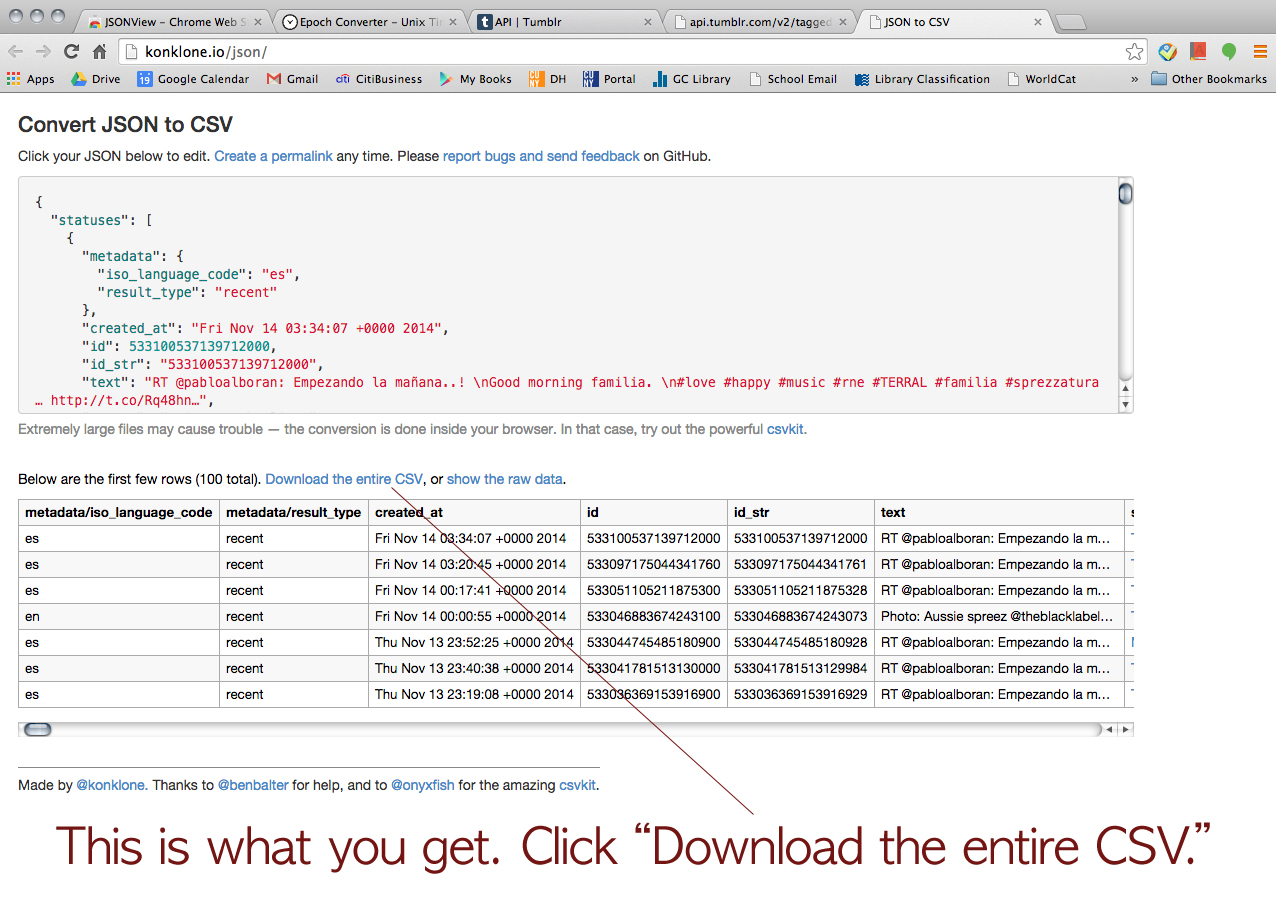
Click this URL > http://www.epochconverter.com/
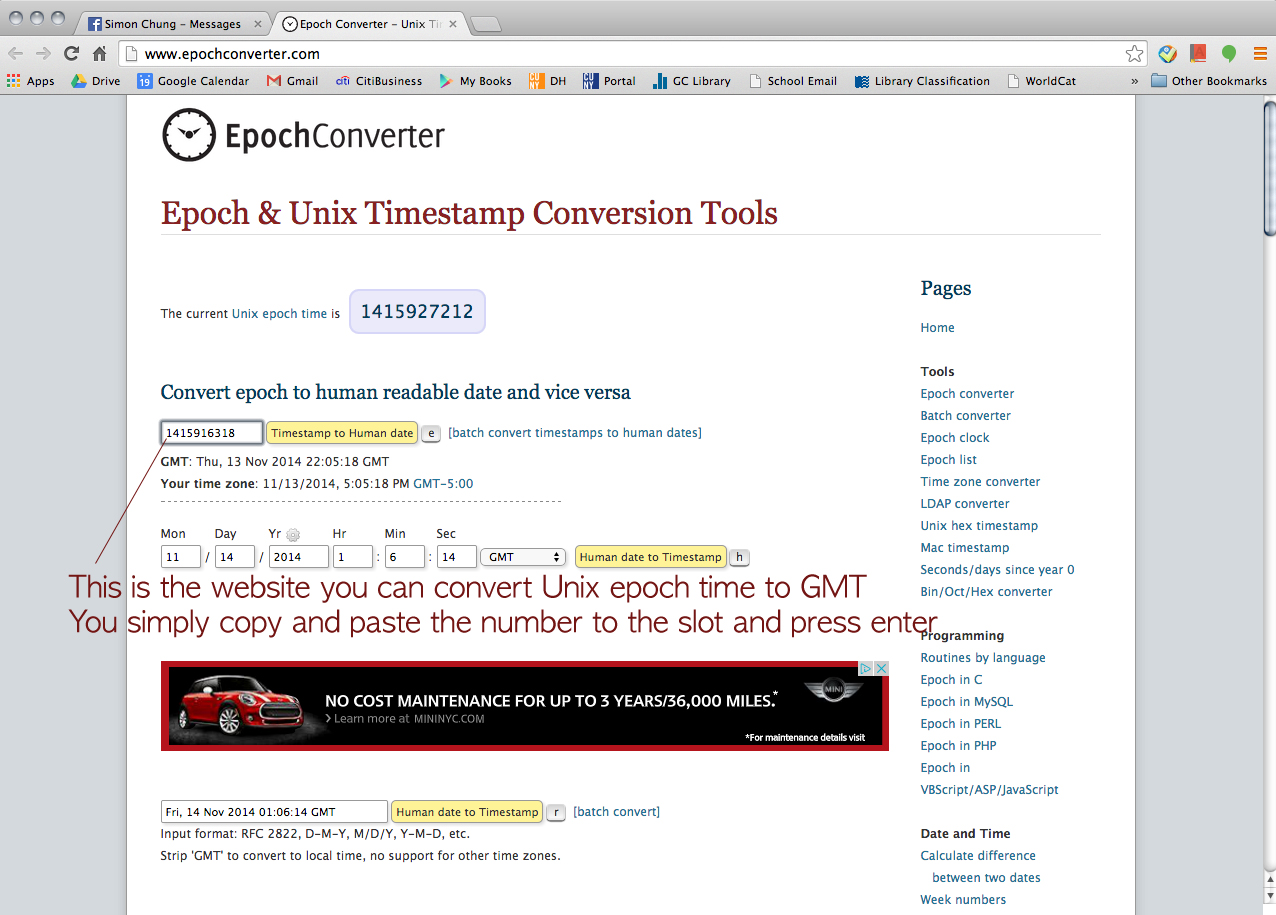
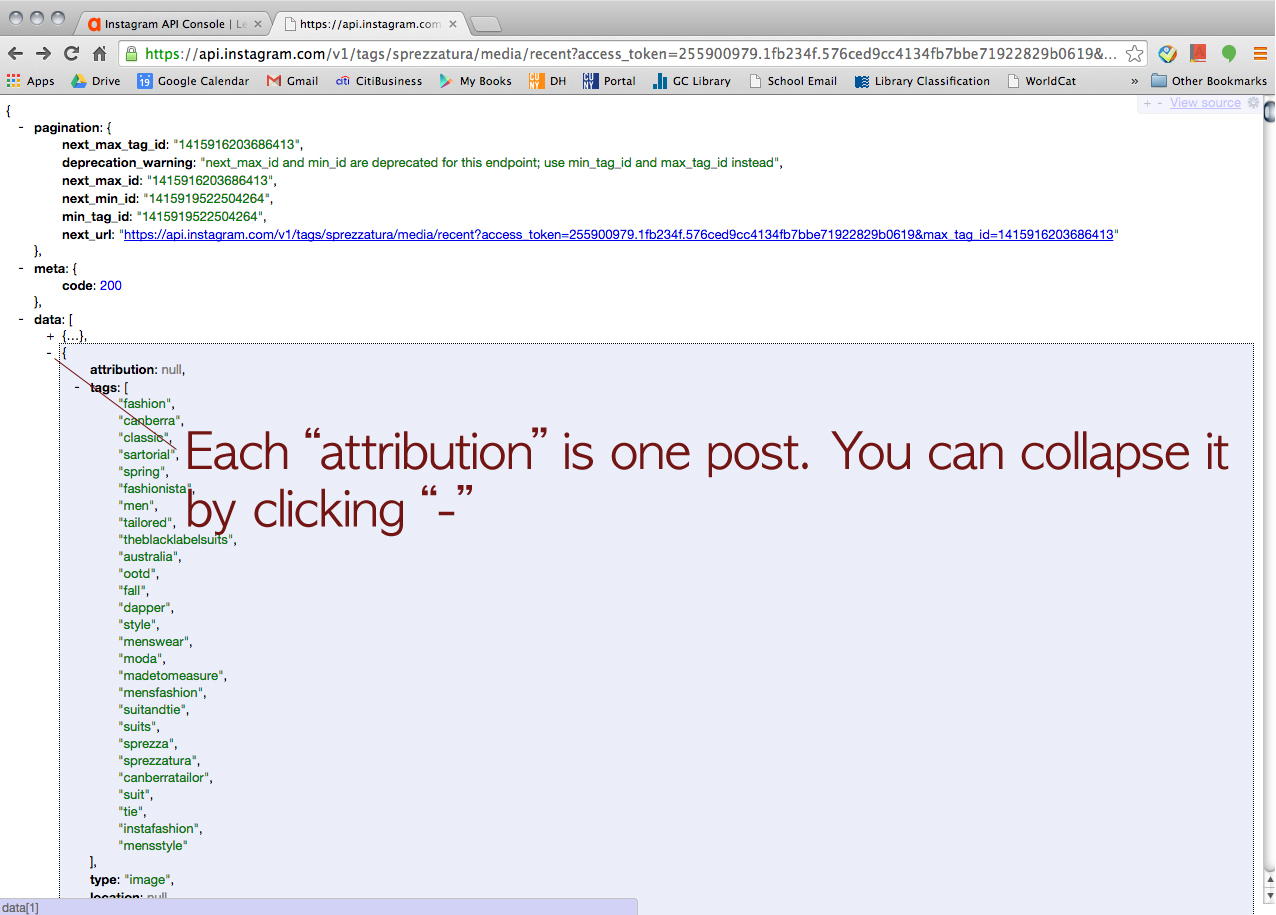
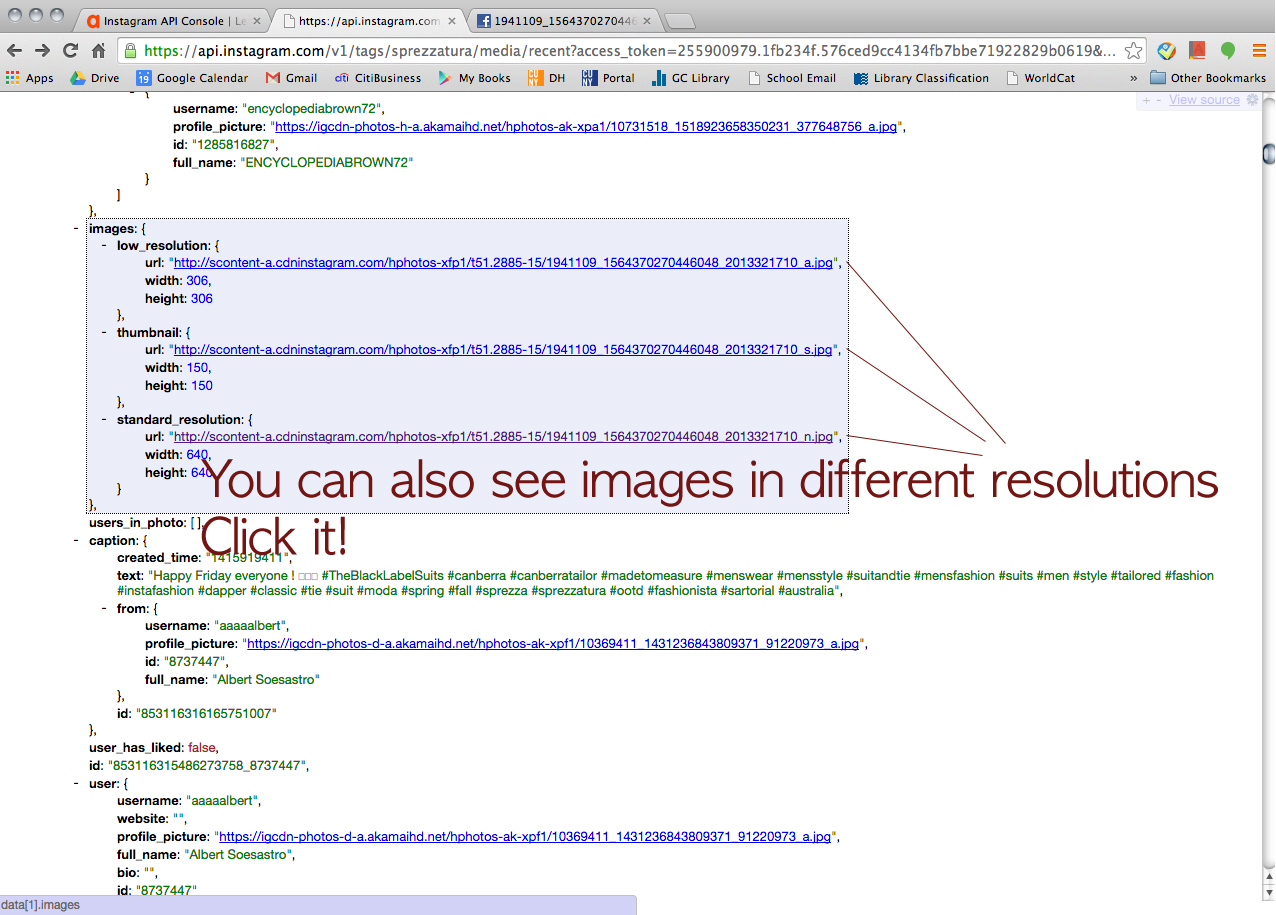
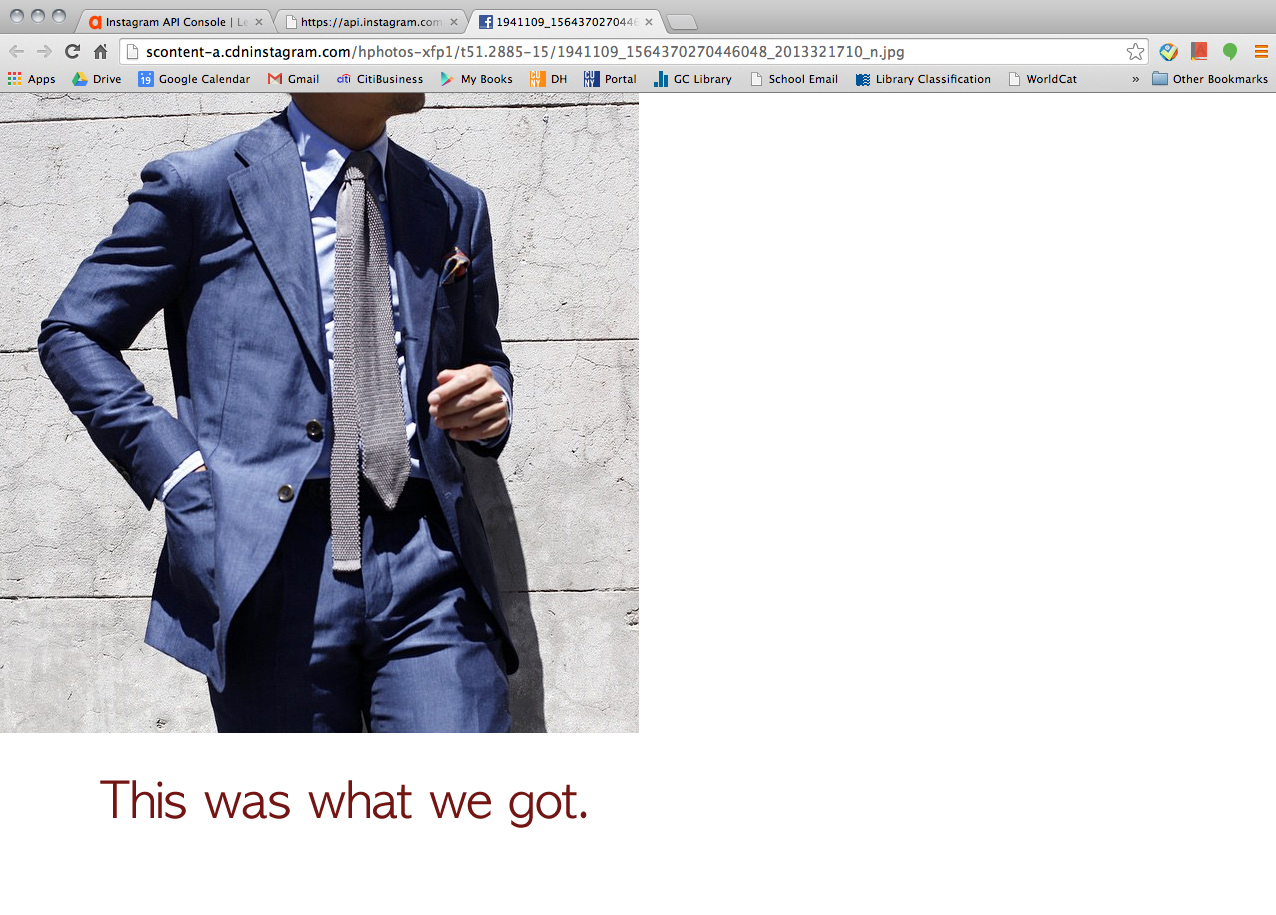
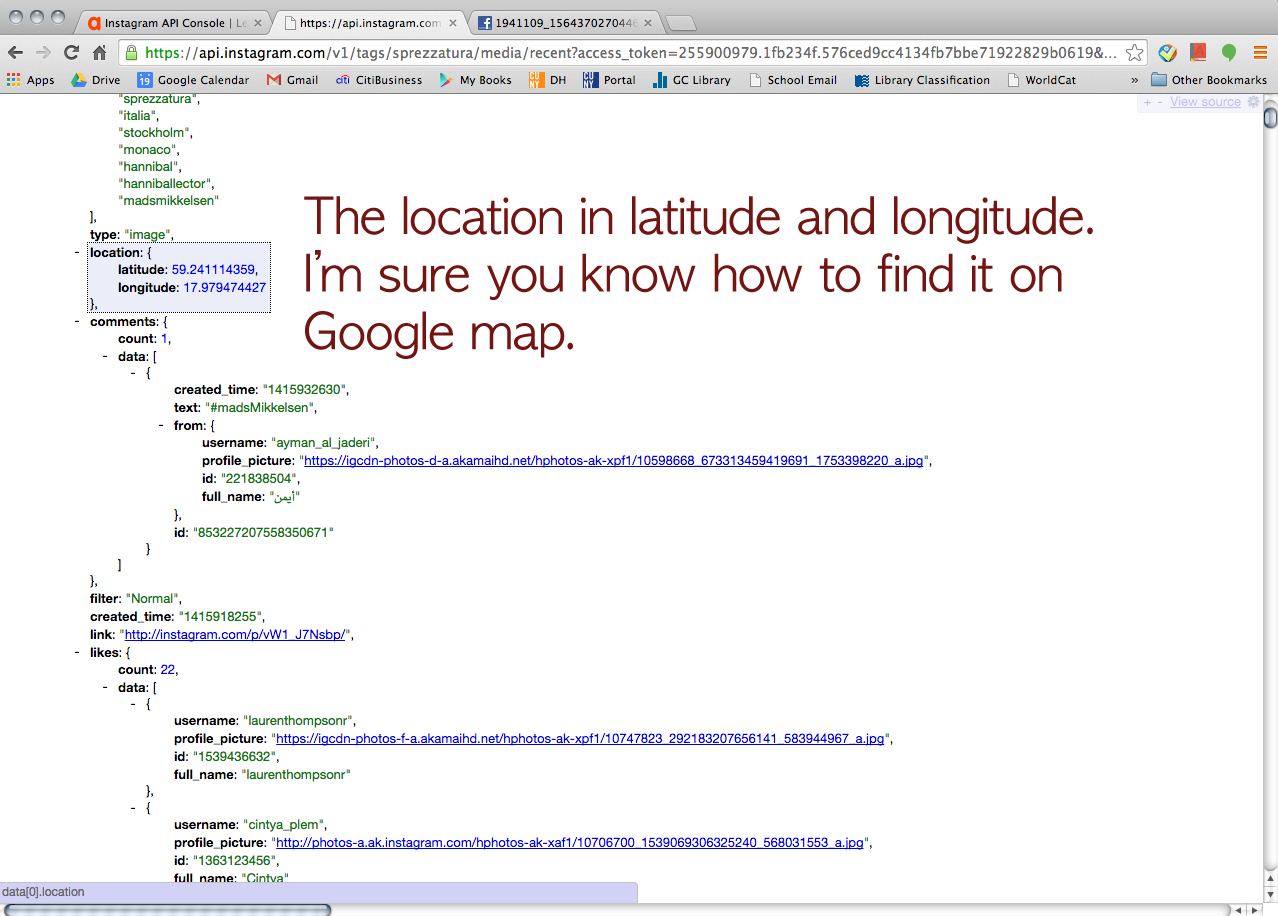
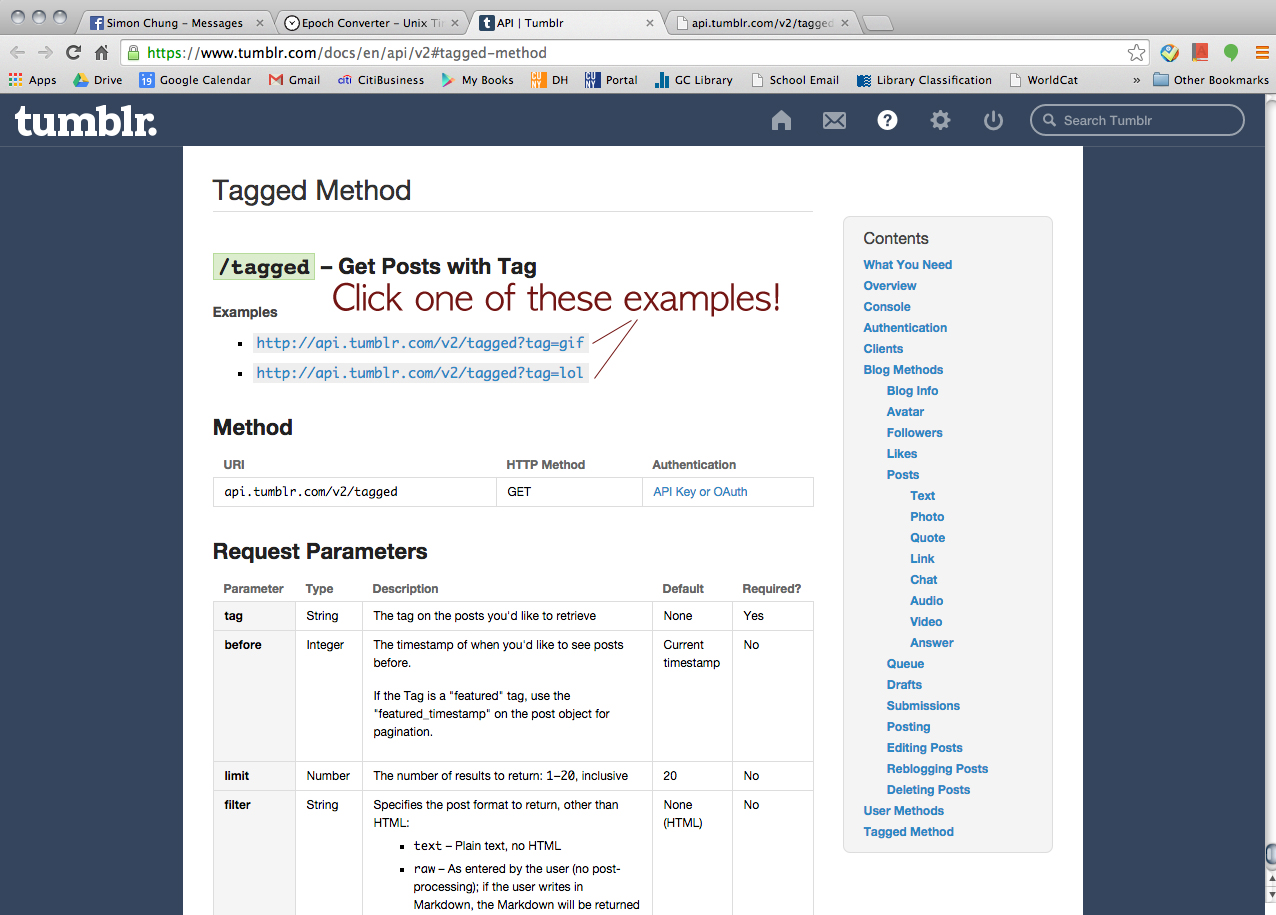
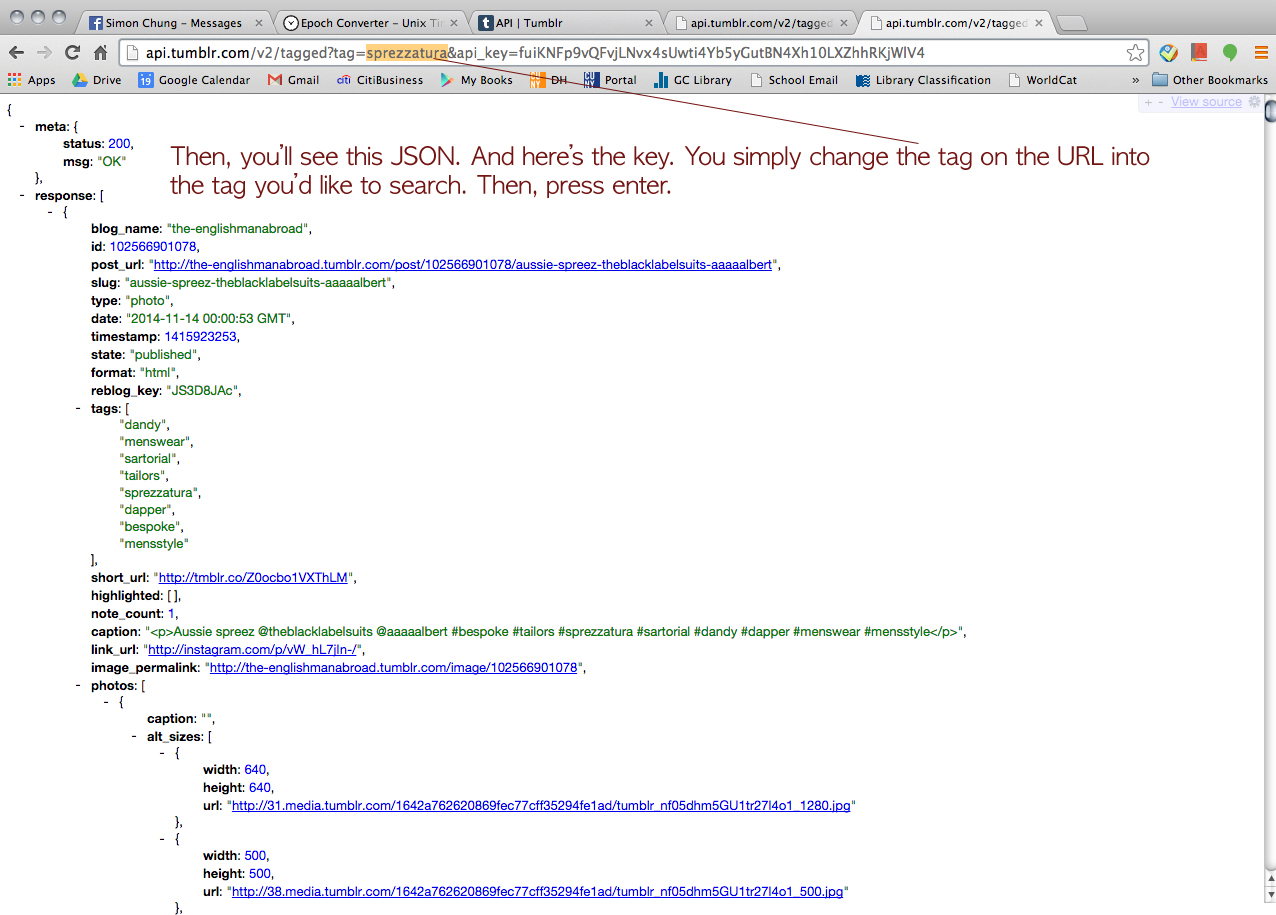
Then, we wanted to try Tumblr but he said, for some reason, Apigee didn’t let him retrieve data from Tumblr. But he could find a way to go around and collect the data from Tumblr (a little bit of cheating I guess). Click this URL > https://www.tumblr.com/docs/en/api/v2#tagged-method
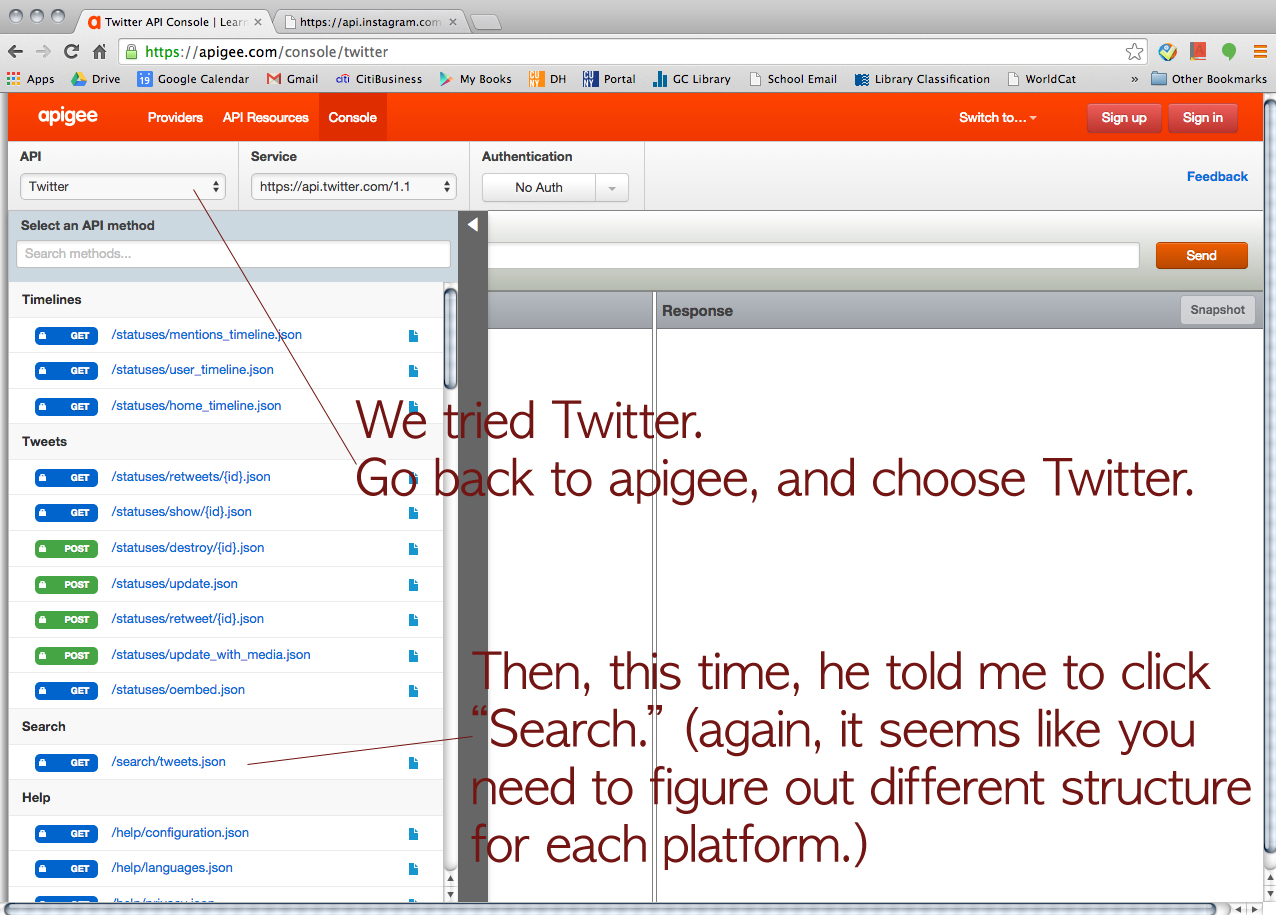
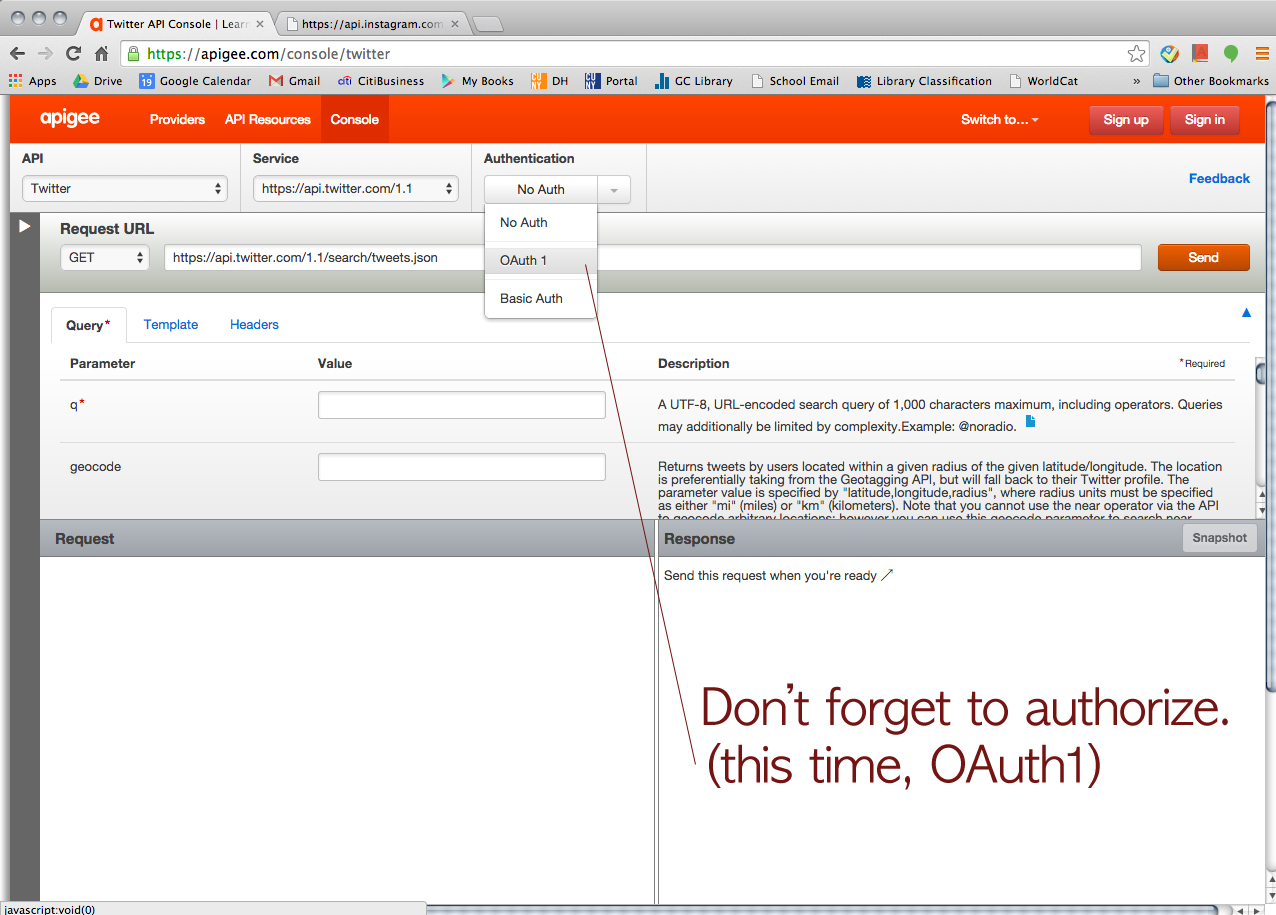
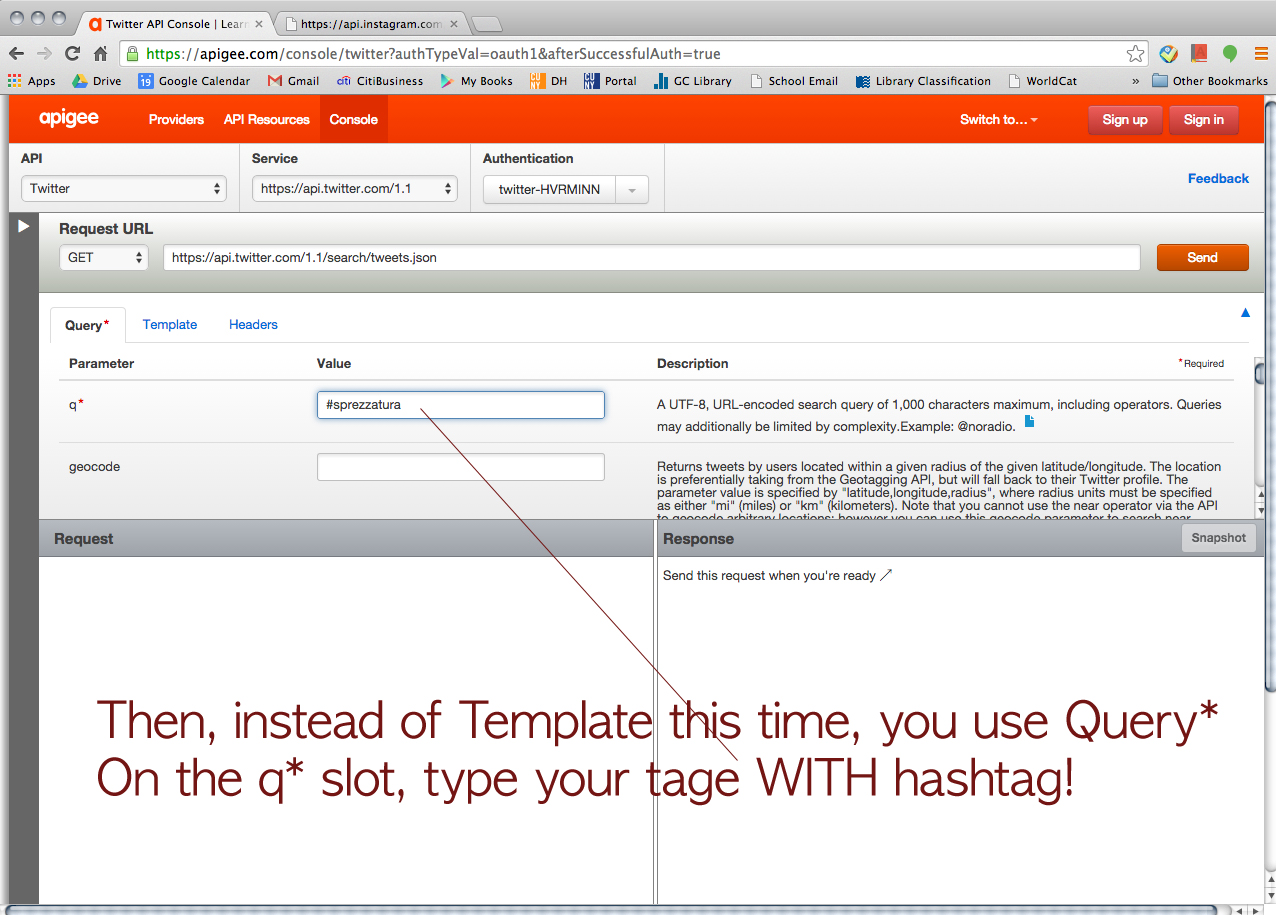
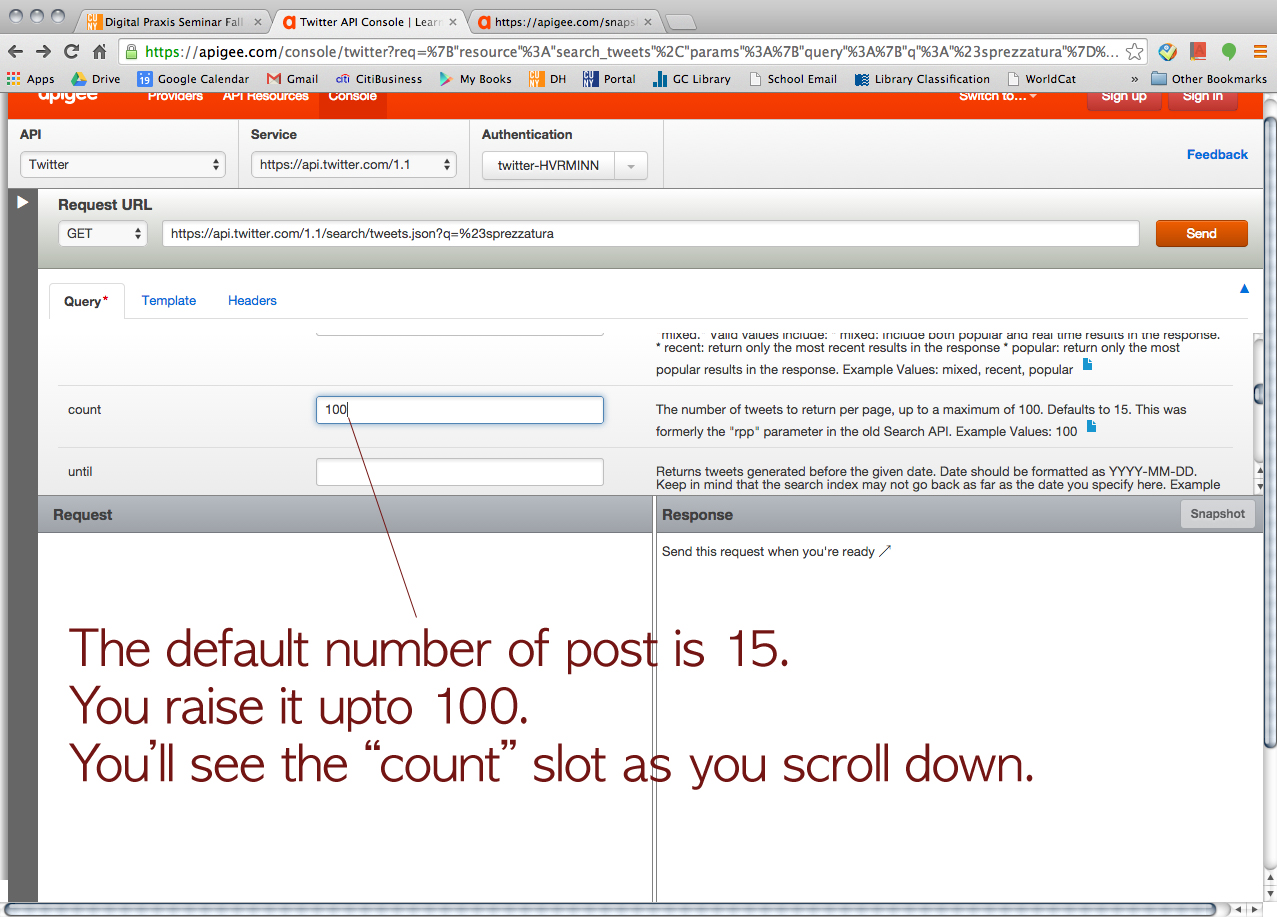
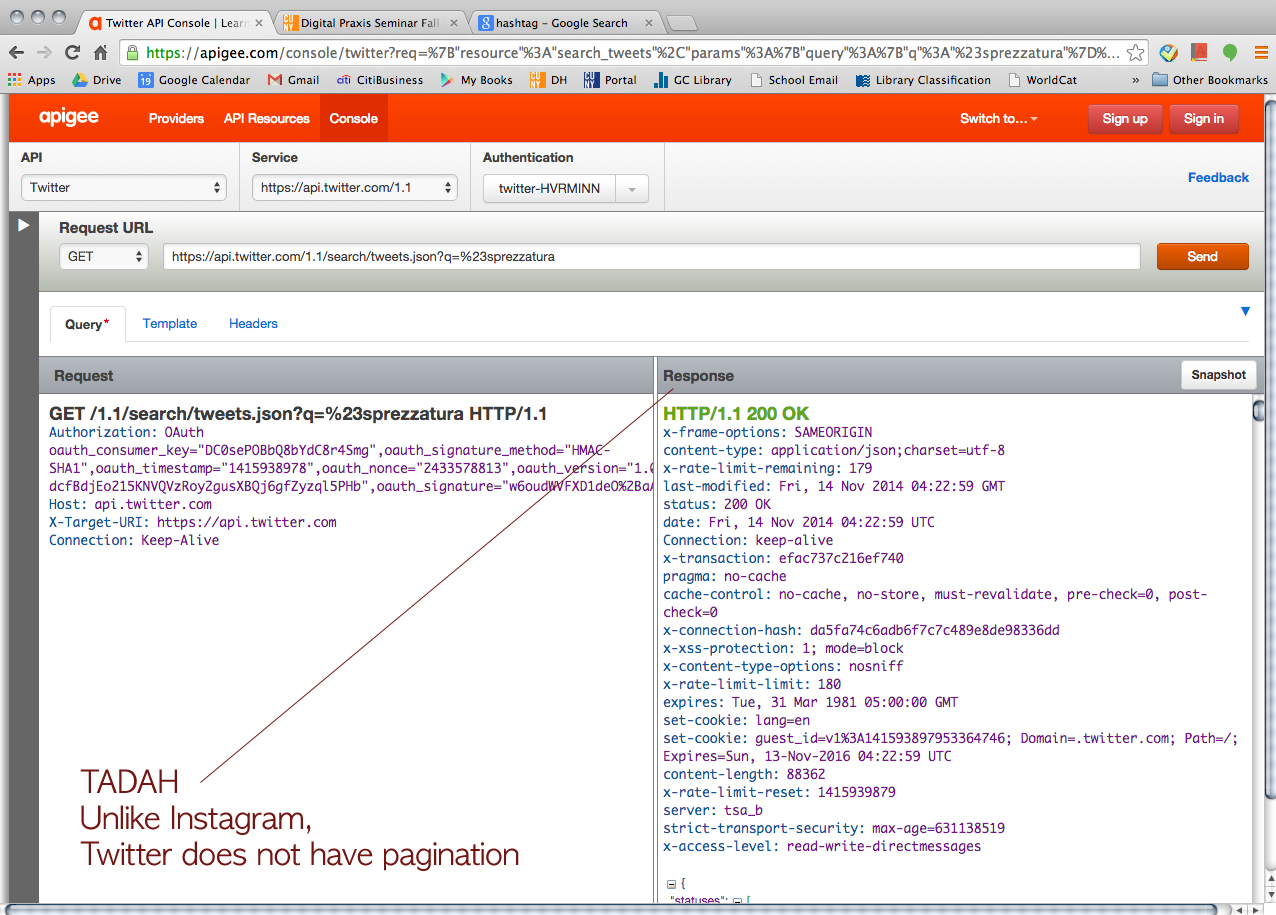
Then, we tried Twitter just for fun.
I am definitely going to try this later. Thanks for being so detailed (and solving the JSON riddle!)
Thank you, Tessa and Min!
How incredibly helpful and clear!
Great use of screenshots to show your process! Thanks. MJR
Fascinating. Do you know if there’s a way this program can track the “Likes” a post gets in tumblr and the location of the posters doing the liking?
One project I have in mind isn’t tracking a specific tag, but rather tracking the locations of people that like certain content creators.
Renzo, I’m not quite sure how to do it but it does seem like there’s a way to do it.
It seems like you need a media-id for the post that you’d like to track the liking.
http://instagram.com/developer/endpoints/likes/
Alright, Renzo, I think I just figured out how to track the likes for a certain post. But unfortunately it does not provide the locations. It does provide the id numbers though. Here’s one of the examples,
“username”: “figs__”,
“bio”: “Minimal fashion.\nLiterature. \n6’4”,
“website”: “http://figs3.tumblr.com”,
“profile_picture”: “https://igcdn-photos-f-a.akamaihd.net/hphotos-ak-xap1/10665927_1481043782180037_934581162_a.jpg”,
“full_name”: “Daniel Figueroa”,
“id”: “31226107”
Fabulous rich detail on the process that can apply seamlessly to other projects. Thank you.
As so many others have pointed out, not only is your documentation so wonderful and clear, but the methodology itself is really solid. Your steps are really logical, and thinking about “reproducible research” as a cornerstone of data inquiry, I think your work easily passes this test.
Such exciting work!