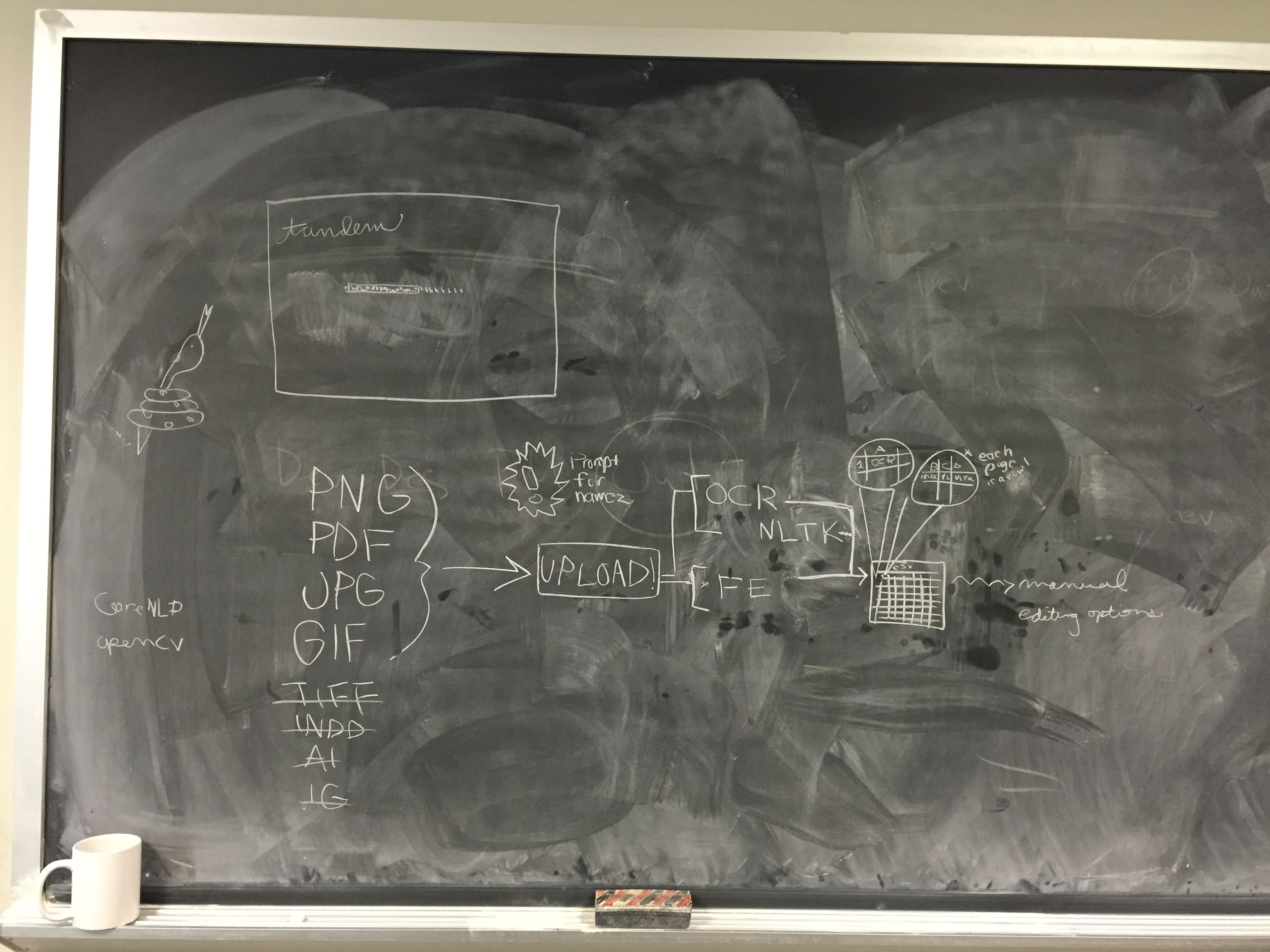
WEEK 13 TANDEM PROJECT UPDATE:
We are happy to announce that the initial version of our near-polished UI is up and functioning on http://dhtandem.com/. This development means that you can now go to the site and walk through uploading files as well as review some early versions of our documentation.
Immediate next steps for our team include updating the text on the documentation pages to the more robust things we have patiently waiting in the wings while we finalize the connection of the front and back components of the app. We have been powering away at creating thorough documentation and user information to be present on the final site. This also includes our exploration of the Mother Goose corpus which is beginning to take shape (in part thanks to some TANDEM supporters and volunteers from the praxis class). Basically, we’re pushing our data set through various tools for discovery and analysis. These results will become incorporated in the Sample Data section on the TANDEM website, which is intended as an example of the apps potential, and as a learning tool for new users.
As we continue to work on bugs and high priority action items, such as fixing an error with zipping files that originated from a change in processing in this iteration, we are realizing areas that could use strengthening post-dhpraxis. Our function May 19th MVP is so close we can taste it.
The zipping problem mentioned above may be related to another problem, which only happens on the server and cannot be replicated in a development environment. What appears to happen follows: when a user starts a new project, TANDEM builds three folders on the server, one for the uploaded files, one for the final output which is subsequently zipped for download. The third folder is a staging or intermediate directory that can contains files after any pre-processing that is required. For example, PDF files must be converted to JPG for our image analysis software to work. Another example is that the text must be extracted into TXT files via an OCR step for NLTK to be able to consume the content.
These new folders appear to be created successfully, and their locations are saved to global variables in the program. However, when it comes time to write files to the newly created folders, it seems that the file are being written to a previously used set of folders. The problem is intermittent. To make diagnosis more difficult, the zip step sometimes zips the older folder which delivers content from multiple projects to the user. However, other times the zip step zips the new folder which is empty delivering an empty file to the user. At still other times, the files are all read and written properly.
Zipping issues aside, we are moving along. Given all the amazing progress we have made, it is not surprising that buzz for the launch is growing. (Also Jojo invites anyone and everyone she speaks to). With new details regarding presentations, we are ready to get this party started. The DH community at CUNY and in New York has been a part of these projects whether actively or abstractly, and it seems a grand opportunity to celebrate.