Fashion studies is an interdisciplinary academic field. We believe it strongly bridges to social science areas including sociology, anthropology, and psychology. People who came from fine arts and design studies as well as those who have social science background of studies will show integrating interests to our project.
1. Socioeconomic scholars
They will analyze data from instagram based on geographic information, neighborhood, and economic status. Instagram users tag their location and brand of clothes once they post their ootd (outfit of the day). Based on the information, socioeconomic scholars can predict the users’ economic climate. Depending on neighborhoods and districts, people dress differently. Thus, dress code symbolizes the occupations along with the social classes. Certain clothes are dressed in special occasions to discuss social or political issues and to give messages.
2. Psychologists
Fashion is a form of expressing oneself. Psychologists can predict what certain groups of people want to express through their clothing. They can also read the psychological fabrics of the people through patterns, colors, and styles. What’s more, fashion is deeply related to the psychology of the consumers, and psychologists can analyze and predict its trend. Personal style without chasing the trends defines one’s identity through what one is wearing and reflects strong points what looks good on one’s body shape.
3. Costume Designers
They work on the design of items of clothing and pay attention to specific reference materials especially textiles and colors. They will get inspiration to design their clothes for the performers especially from film and broadcasting. In particular, costume designers are responsible for overall look of the clothes and costumes in theatre, film, or television producers. They need to have excellent design skills as well as organization skills to lead the team. They should also reflect the socioeconomic and psychological aspects of the people’s life in different backgrounds.
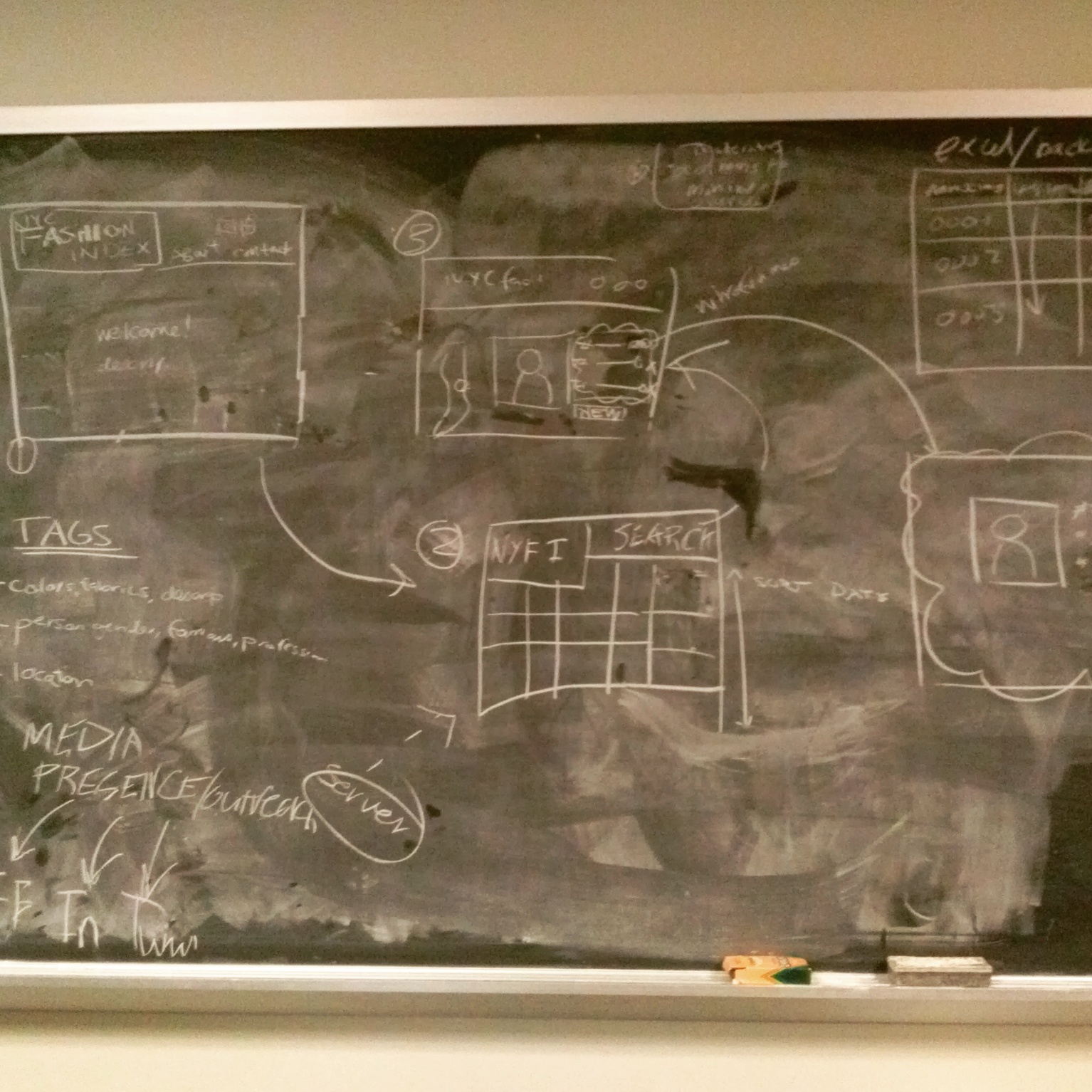
In this project, we aim to provide straight facts about the who, what, when, where. The tags will be listed by either the initial user or added by crowdsourcing.