SHOUT IT OUT WITH CUNYcast!
CUNYcast is moving forward and expanding our knowledge of the technical requirements involved in online radio broadcast. This week major strides were taken in outreach and development.
- Contact was made with support and specialty knowledge in online radio broadcast technology (Mikhail Gershovich)
- Reclaim hosting server space was finalized
- Icecast and Artime were uploaded to server space.
THE MINIMUM VIABLE PRODUCT (MVP)
CUNYcast is a live online radio website offering students an opportunity to stream audio using original content from classes, lectures, and projects. CUNYCast’s aim is to empower a DH guerrilla broadcast community.
CUNYcast will reach out to the GC through an academic commons page that will link users, listeners, and curious DHers to our CUNYcast web presence. The CUNYcast web page will have a space for listeners to listen to the live streaming CUNYcast content. It will have a space where users may learn how to access the CUNYcast live stream and upload their own content. CUNYcast is designed to inform and inspire its users, to facilitate this experience CUNYcast’s web page will house a manual that will empower user’s to add their own content to the CUNYcast live streaming radio and inform them on how they could create their very own digital live stream radio channel. A portion of the manual will help users learn how to create their own audio content if the wish to explore a more polished radio stream format.
As an added bonus the CUNYcast website will have links to educational audio content and pedagogy surrounding teaching practices that utilize audio creation as mode of production.
Technical specifications for MVP
The technical map of CUNYcast lays in the Icecast media server and the Airtime client used to manage media on the media server. This back end structure will be given its public face on our website and our cuny commons presence.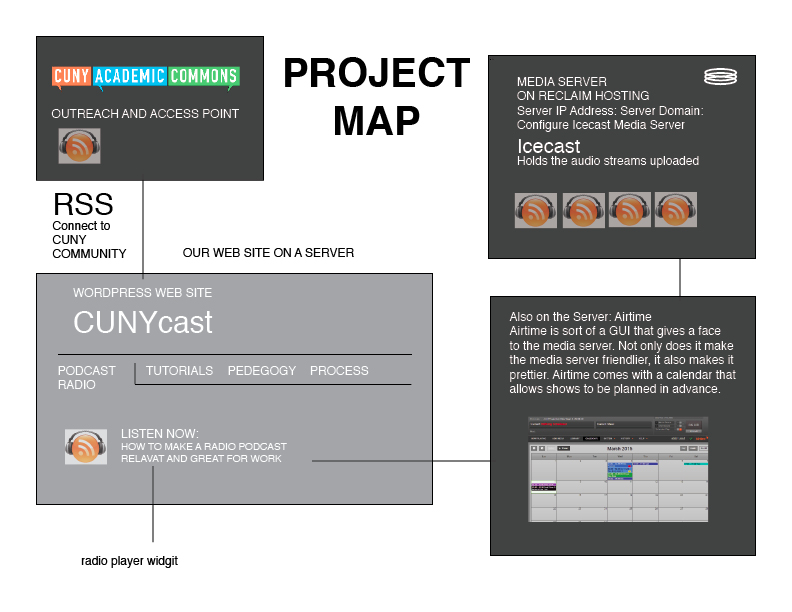
Outreach: Report of activities to date
How To Succeed Even When You Fail
Spring semester 2015. Our Digital Humanities class broke into teams. We were only mildly anxious. Like the television show, “Shark Tank” which features new pitches for products and services each week, we were convinced our ideas were sound and that we could excel. The thing was, within just a few days we started to drown. Instead of devouring the material and spitting it back out for human consumption, we started sinking in a sea of possibilities. No tech geeks on our team. Just dreamers. That didn’t stop us from grabbing at every idea that seemed to float.
But, wait, our group of four people diminished to only three by week two. Man down. He disappeared and dropped the class (we wished him well). The three of us had to take a good hard look at the CUNYcast concept and decide what would assure our chances of survival. (Think of the music to Jaws playing underneath these words).
We took our overblown idea of a RSS-feed calendar linked into the CUNY system, that would record remotely via an app, after two afternoons of staring at code and realizing that by the time the project was due, we’d maybe have gotten through a couple of introductory tutorials. There was no way any of us would be coding experts in 12 weeks.
We trimmed the fat. Bit back with strength and vigor, and began on the current instantiation of CUNYcast: a live online radio website offering students an opportunity to stream audio using original content from classes, lectures, and projects. Our professors urged us to aim outside the box and empower an entire DH guerrilla broadcast community at the Graduate Center. Reporting in on week 4 and things are going swimmingly. We’ve gelled as a team and we’re optimistic.
We are not afraid anymore We are not afraid anymore – even if we should be.
Development:
This week, the goal was to configure an Icecast Media server in a local environment.Airtime and Icecast were configured on our server when we received the server configuration thanks to Reclaim hosting.
Icecast is (again) a media server. When you have an online radio station, the media server is where the audio/video lives for the duration of the stream, sort of an intermediary between the streamer (host machine) and the watcher (listener). Airtime is sort of a GUI that gives a face to the media server. Not only does it make the media server friendlier, it also makes it prettier. Airtime comes with a calendar that allows shows to be planned in advance.
One interesting thing about media servers, is that if someone has the access information to an Icecast server (ds106 allows their’s to be public, as will we, that’s kind of the point) they can use broadcasting programs to take over the station. If another person tries to take over the station when a show is going on, they’ll be met with an error. Airtime simplifies this with the above-mentioned calendar feature, as it allows users to see when shows are planned, and as such, schedule their planned broadcasts around that. Of course, this also allows for anarchy…
Bugs! The Icecast Server worked perfectly. We were able to access it via broadcasting software (Mixxx) and pick up that broadcast via VLC and browser (the address currently being cunycast.net:8000/live, kind of ugly) . However, Airtime specifically had some trouble connecting to our Icecast server, even after multiple troubleshooting attempts. When transmitting via Airtime, a connection could be established to the Icecast server for roughly ~10 seconds before falling flat, despite Airtime claiming the show was still airing. I hate it when machines lie to me. Anyway, after doing some GoogleFu I came across a thread on the SourceFabric forums (SourceFabric developed Airtime) about this exact problem. The fix stated in the thread claimed that I needed to restart certain Airtime services via commandline using the “sudo” command. Sounds scary. Because Airtime was installed for us, I was a little worried about messing it up, fearing that I would have to reinstall things that I do not understand. However, we were able to fix the bug more easily, by switching the broadcasting format from OGG Vorbis to simpler MP3 format.
development goals include:
- Figure out how to interact with Airtime via command line (need help from Digital Fellows here)
- Bring the backend media server to the front ASAP such that we have a simpler/prettier way for users to tune in.
- Implement an AutoDJ to play over the station and maintain it when no broadcasts are coming in (this is where we may need to talk to a ds106 person).
- Determine how incoming users will be able to manipulate/interact with Airtime.
Design:
Slow progress is being made constructing the structure and elements to the CUNYcast web presence using Bootstrap. The pre organized Java and CSS allows for immediate product but there is still a bit to understand about the addition of and linking to media.
The CUNYcast Academic commons site is being designed to mirror the CUNYcast website.
The guide on how to create websites is being updated to make sure that the CUNYcast manual evolves as the project evolves.