During the class discussion, we had an issue of staid version vs. dynamic version of our website. Since we are running out of time, we may not be able to cover database. So we ended up continuing the static one. We need to navigate data between mapping. As well as, we have to navigate tags based on time, space-csv scripts.
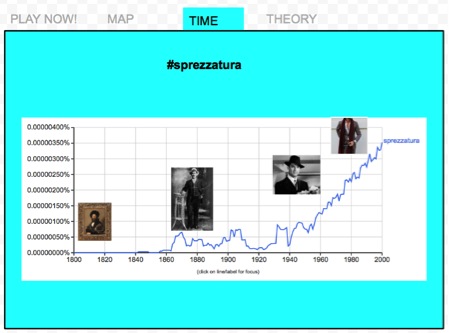
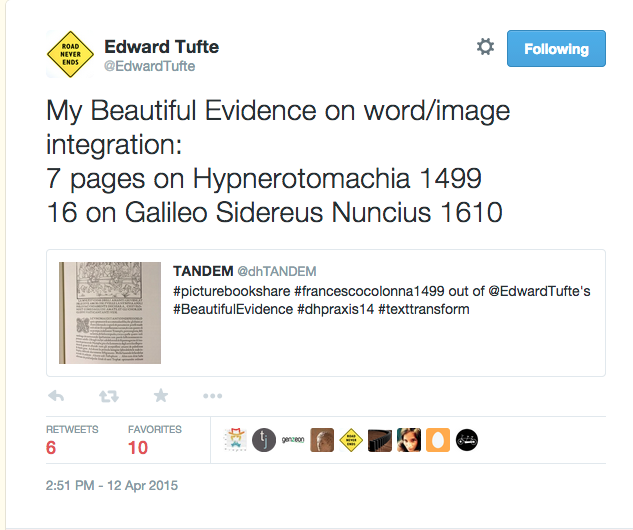
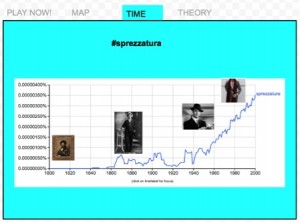
At this point, feedback loop is critical, which refers to increase more users engagement such as tagging more maps and bringing more images related to #sprezzatura. Anyway, we will stick around #sprezzatura instead #nyfw (New York Fashion Week).
In our website, there is a theory section, we may fill up with 500-1000 essays written by fashion studies related scholars. We expect that those essay will be a strong part of the user stories.
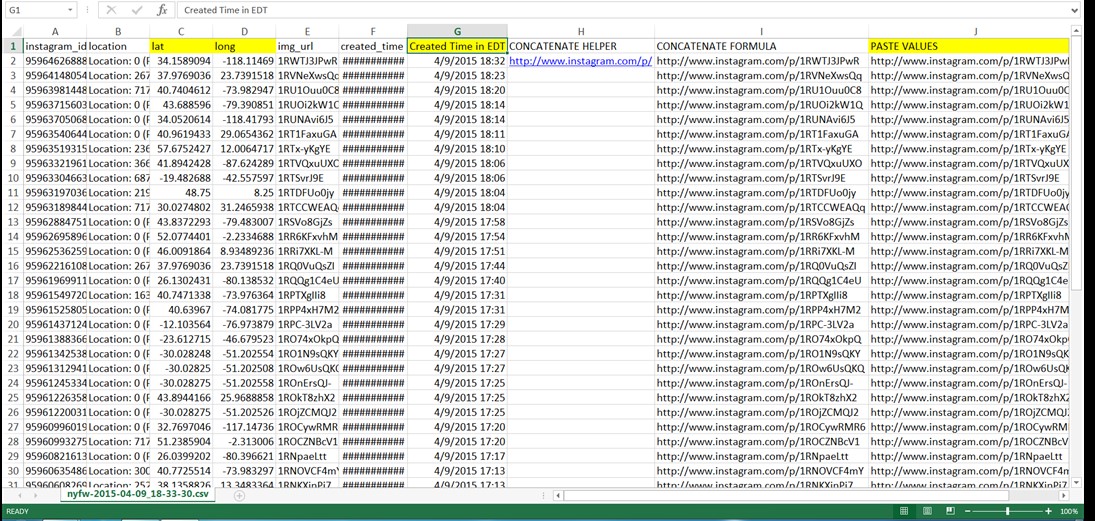
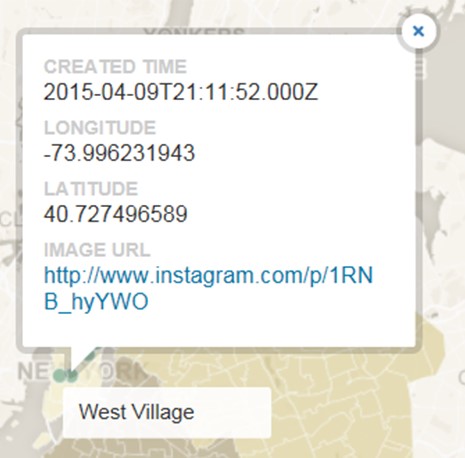
The developer, Tessa’s plan is to explore more new tags, implement retroactive geographical filters, populate tags from NY (few images, which will be trend-bases). Definitely, cleansing the datasets, which are not totally related to #sprezzatura, is very important. The images should be credible. We can easily find several irrelevant images in relation to the hash tags, which we are mainly looking for. We will set our own parameter to avoid the random images. Also, Tessa is going to work on geocoding, the main function is searching addresses based on on zip codes, longitude, and latitude. The data came from Python script. Geo-specific data, “reversing geocoding” convert zip codes to longitude and latitude.
We made slight changes on our website. For our introduction page, we displayed datasets of images, which will be shuffled around in black and white. Then, we added dataset section.
Renzo made questionnaires in order to get feedbacks and they are composed of multiple choices and short sentences.
According to Dave Rioden from NYPL, we should focus on the interaction or engagement with users. We are planning to set up a server that will archive game data. DH and Fashion Studies students will test out the game.
Lastly, we got 24 follower on our Instagram account. Undergraduate fashion school students and a fashion blogger followed us. We should facilitate more chances of interaction and communication.